
AGI 帧分析器允许您通过从我们的一个渲染过程选择绘制调用,并遍历**管道**面板的**顶点着色器**部分或**片段着色器**部分来调查您的着色器。
在这里,您将找到来自着色器代码静态分析的有用统计信息,以及我们的 GLSL 已编译到的标准可移植中间表示 (SPIR-V)汇编。还有一个选项卡用于查看使用 SPIR-V 反编译的原始 GLSL(带有编译器生成的变量、函数等的名称)的表示,以便为 SPIR-V 提供更多上下文。
静态分析
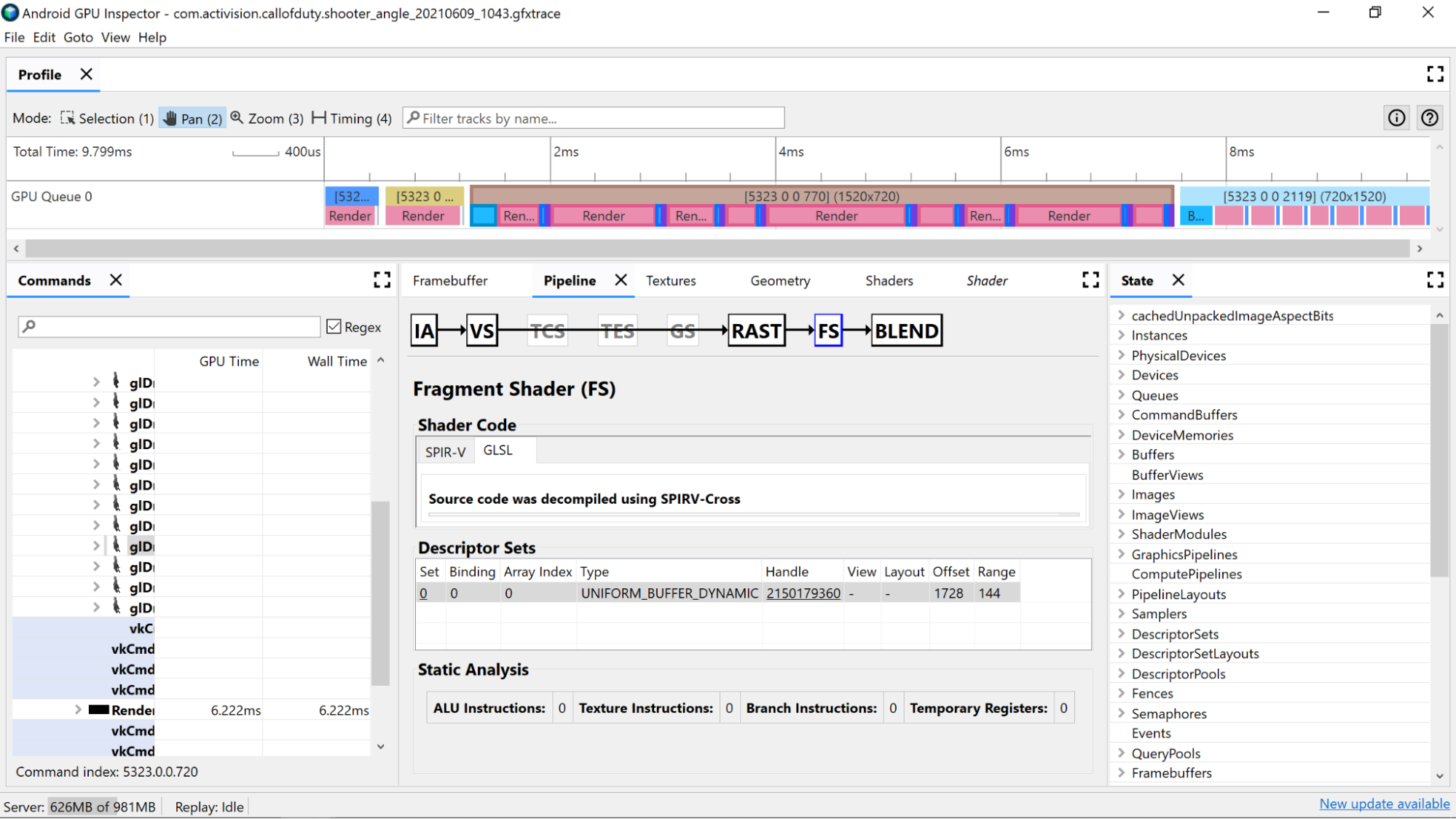
使用静态分析计数器查看着色器中的低级操作。
ALU 指令:此计数显示着色器中执行的 ALU 操作(加法、乘法、除法等)的数量,并且是着色器复杂程度的一个很好的指标。尝试最小化此值。
重构公共计算或简化着色器中完成的计算可以帮助减少所需的指令数量。
纹理指令:此计数显示着色器中纹理采样发生的次数。
- 根据所采样的纹理类型,纹理采样可能非常昂贵,因此将着色器代码与在**描述符集**部分中找到的绑定纹理交叉引用可以提供有关所使用纹理类型的更多信息。
- 采样纹理时避免随机访问,因为此行为对于纹理缓存来说并不理想。
分支指令:此计数显示着色器中分支操作的数量。在并行处理器(如 GPU)上,最小化分支是理想的,甚至可以帮助编译器找到其他优化。
- 使用诸如
min、max和clamp之类的函数来避免需要根据数值进行分支。 - 测试计算成本与分支成本。因为在许多架构中都会执行分支的两个分支路径,所以有许多情况下,始终进行计算比使用分支跳过计算要快。
- 使用诸如
临时寄存器:这些是快速的、片上寄存器,用于保存 GPU 计算所需的中间操作的结果。在 GPU 必须溢出到使用其他片外内存来存储中间值(从而降低整体性能)之前,可用寄存器的数量是有限制的。(此限制因 GPU 型号而异。)
如果着色器编译器执行诸如展开循环之类的操作,则使用的临时寄存器数量可能高于预期,因此最好将此值与 SPIR-V 或反编译的 GLSL 交叉引用以查看代码正在执行的操作。
着色器代码分析
调查反编译的着色器代码本身,以确定是否有任何可能的改进。
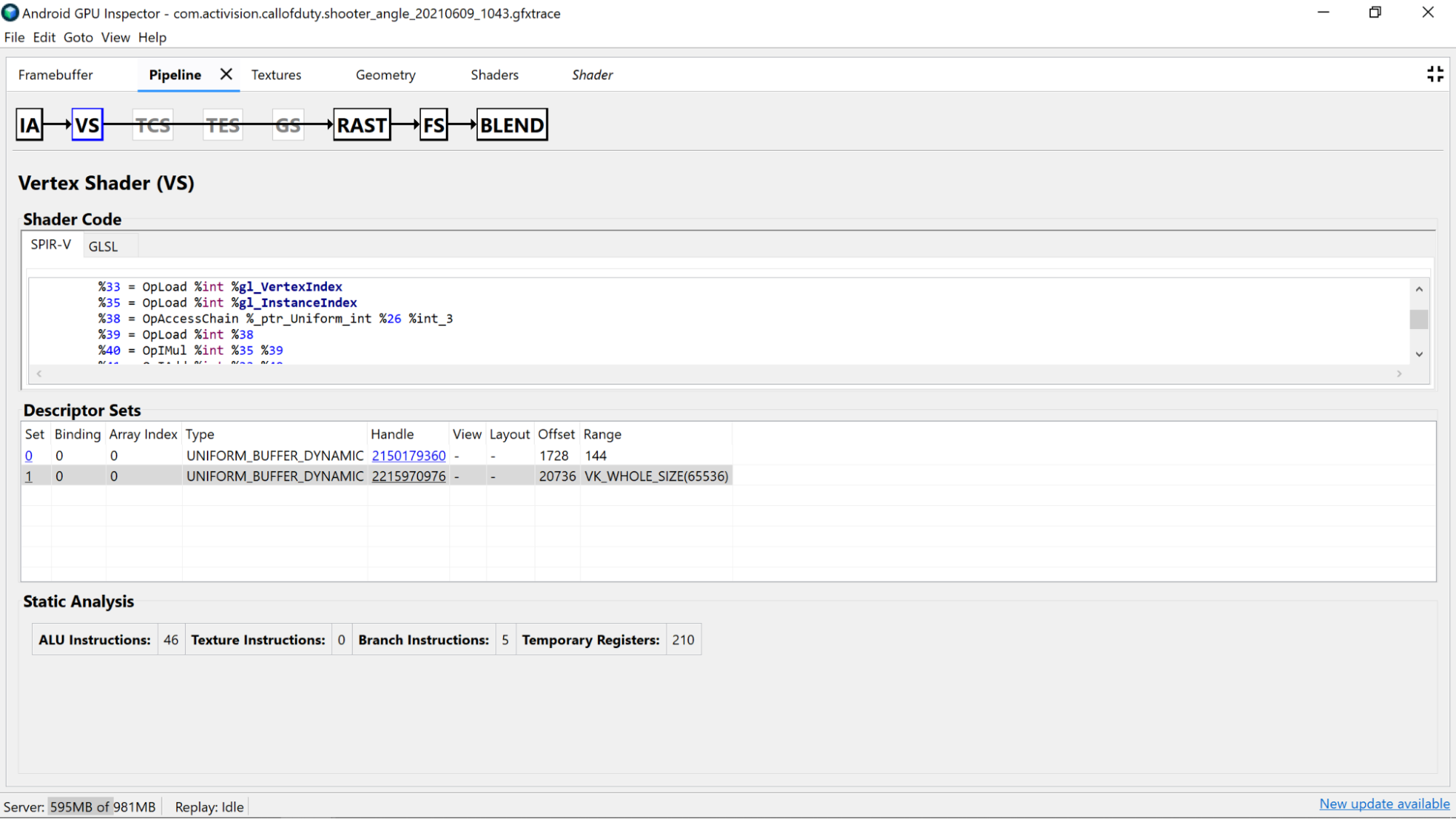
- 精度:着色器变量的精度会影响应用程序的 GPU 性能。
- 尽可能在变量上使用
mediump精度修饰符,因为中等精度 (mediump) 16 位变量通常比全精度 (highp) 32 位变量更快且更节能。 - 如果您在着色器上变量声明中没有看到任何精度限定符,或者在着色器顶部使用
precision precision-qualifier type,则默认为全精度 (highp)。请务必查看变量声明。 - 出于上述相同原因,最好使用
mediump作为顶点着色器输出,并且这样做还有助于减少执行插值所需的内存带宽和潜在的临时寄存器使用量。
- 尽可能在变量上使用
- 统一缓冲区:尝试尽可能减小统一缓冲区的大小(同时保持对齐规则)。这有助于使计算更兼容缓存,并可能允许将统一数据提升到更快的片上寄存器。
删除未使用的顶点着色器输出:如果您发现片段着色器中未使用顶点着色器输出,请将其从着色器中删除以释放内存带宽和临时寄存器。
将计算从片段着色器移动到顶点着色器:如果片段着色器代码执行与特定于正在着色片段的状态无关的计算(或可以正确插值),则将其移动到顶点着色器是理想的。原因是在大多数应用程序中,与片段着色器相比,顶点着色器的运行频率要低得多。