
与大多数其他 UI 工具包一样,Compose 通过几个不同的阶段渲染帧。如果我们查看 Android View 系统,它有三个主要阶段:测量、布局和绘制。Compose 非常相似,但在开始时有一个重要的附加阶段,称为组合。
组合在我们的 Compose 文档中进行了描述,包括Compose 思维模式和状态和 Jetpack Compose。
帧的三个阶段
Compose 有三个主要阶段
- 组合:显示什么UI。Compose 运行可组合函数并创建 UI 的描述。
- 布局:UI 的位置。此阶段包括两个步骤:测量和放置。布局元素测量并放置自身以及布局树中每个节点的任何子元素的二维坐标。
- 绘制:如何渲染。UI 元素绘制到画布中,通常是设备屏幕。

这些阶段的顺序通常相同,允许数据从组合到布局再到绘制单向流动以生成帧(也称为单向数据流)。BoxWithConstraints和LazyColumn和LazyRow是值得注意的例外,其中其子元素的组合取决于父元素的布局阶段。
您可以安全地假设这三个阶段实际上发生在每一帧中,但为了性能,Compose 避免重复计算在所有这些阶段中从相同输入计算相同结果的工作。Compose 跳过运行可组合函数,如果它可以重用以前的 结果,并且 Compose UI 如果不必重新布局或重新绘制整个树。Compose 只执行更新 UI 所需的最低限度的工作。这种优化之所以可能,是因为 Compose 跟踪不同阶段内的状态读取。
了解阶段
本节更详细地描述了为可组合项执行的三个 Compose 阶段。
组合
在组合阶段,Compose 运行时执行可组合函数并输出表示 UI 的树状结构。此 UI 树由布局节点组成,其中包含下一阶段所需的所有信息,如下面的视频所示
图 2. 在组合阶段创建的表示 UI 的树。
代码和 UI 树的一个子部分如下所示
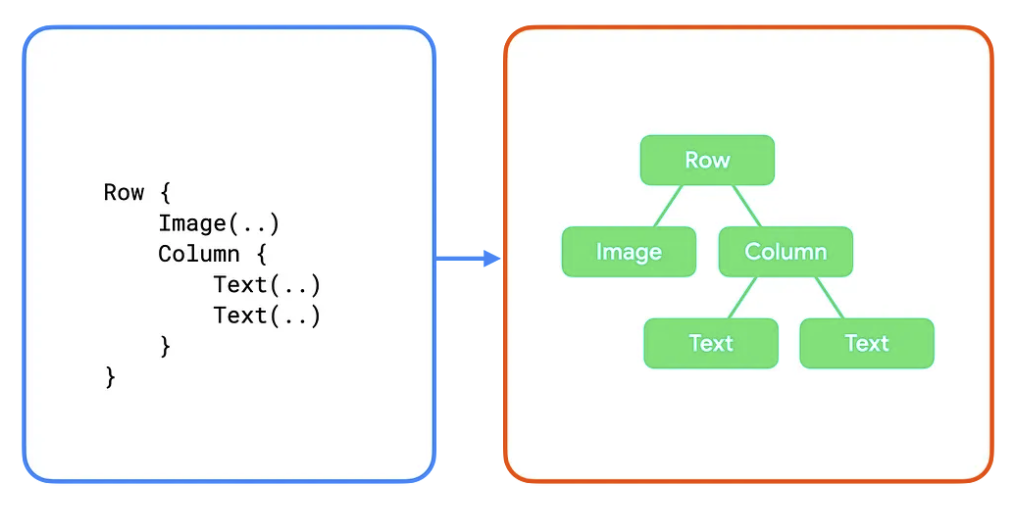
在这些示例中,代码中的每个可组合函数都映射到 UI 树中的单个布局节点。在更复杂的示例中,可组合项可以包含逻辑和控制流,并在给定不同状态的情况下生成不同的树。
布局
在布局阶段,Compose 使用组合阶段生成的 UI 树作为输入。布局节点的集合包含决定每个节点在二维空间中的大小和位置所需的所有信息。
图 4. 在布局阶段 UI 树中每个布局节点的测量和放置。
在布局阶段,使用以下三步算法遍历树
- 测量子节点:如果存在任何子节点,则节点会测量其子节点。
- 确定自身大小:基于这些测量结果,节点确定其自身的大小。
- 放置子节点:每个子节点相对于节点自身的位置进行放置。
在此阶段结束时,每个布局节点都具有
- 已分配的宽度和高度
- 应绘制其x、y 坐标
回想一下上一节中的 UI 树
对于此树,算法的工作方式如下
Row测量其子节点Image和Column。Image被测量。它没有任何子节点,因此它确定自身的大小并将大小报告回Row。- 接下来测量
Column。它首先测量自己的子节点(两个Text可组合项)。 - 第一个
Text被测量。它没有任何子节点,因此它确定自身的大小并将大小报告回Column。- 第二个
Text被测量。它没有任何子节点,因此它确定自身的大小并将大小报告回Column。
- 第二个
Column使用子节点测量结果来确定其自身的大小。它使用最大子节点宽度及其子节点高度的总和。Column相对于自身放置其子节点,将它们垂直放置在彼此下方。Row使用子节点测量结果来确定其自身的大小。它使用最大子节点高度及其子节点宽度的总和。然后它放置其子节点。
请注意,每个节点只访问一次。Compose 运行时只需要遍历 UI 树一次即可测量和放置所有节点,从而提高性能。当树中节点的数量增加时,遍历它所花费的时间以线性方式增加。相反,如果每个节点被访问多次,则遍历时间呈指数级增长。
绘制
在绘制阶段,再次从上到下遍历树,每个节点依次在屏幕上绘制自身。
图 5. 绘制阶段在屏幕上绘制像素。
使用前面的示例,树内容以以下方式绘制
Row绘制它可能具有的任何内容,例如背景颜色。Image绘制自身。Column绘制自身。- 第一个和第二个
Text分别绘制自身。
图 6. UI 树及其绘制表示。
状态读取
当您在上述任何一个阶段读取快照状态的值时,Compose 会自动跟踪读取该值时正在执行的操作。此跟踪允许 Compose 在状态值更改时重新执行读取器,并且是 Compose 中状态可观察性的基础。
状态通常使用mutableStateOf()创建,然后通过两种方式之一访问:直接访问value属性,或者使用 Kotlin 属性委托。您可以在可组合项中的状态中阅读更多相关信息。对于本指南的目的,“状态读取”是指上述两种等效访问方法。
// State read without property delegate. val paddingState: MutableState<Dp> = remember { mutableStateOf(8.dp) } Text( text = "Hello", modifier = Modifier.padding(paddingState.value) )
// State read with property delegate. var padding: Dp by remember { mutableStateOf(8.dp) } Text( text = "Hello", modifier = Modifier.padding(padding) )
在属性委托的底层,使用“getter”和“setter”函数来访问和更新 State 的value。只有当您将属性引用为值时,才会调用这些 getter 和 setter 函数,而不会在创建时调用,这就是上面两种方法等效的原因。
每个当读取状态更改时可以重新执行的代码块都是一个重新启动范围。Compose 跟踪不同阶段中的状态值更改和重新启动范围。
分阶段状态读取
如上所述,Compose 有三个主要阶段,Compose 跟踪每个阶段内读取的状态。这允许 Compose 只通知 UI 的每个受影响元素需要执行工作的特定阶段。
让我们遍历每个阶段并描述在其中读取状态值时会发生什么。
阶段 1:组合
在@Composable函数或 lambda 块内的状态读取会影响组合以及后续阶段。当状态值更改时,重组器会调度重新运行读取该状态值的所有可组合函数。请注意,如果输入没有更改,运行时可能会决定跳过某些或所有可组合函数。有关更多信息,请参阅如果输入没有更改则跳过。
根据组合的结果,Compose UI 运行布局和绘制阶段。如果内容保持不变并且大小和布局不会更改,它可能会跳过这些阶段。
var padding by remember { mutableStateOf(8.dp) } Text( text = "Hello", // The `padding` state is read in the composition phase // when the modifier is constructed. // Changes in `padding` will invoke recomposition. modifier = Modifier.padding(padding) )
阶段 2:布局
布局阶段包括两个步骤:测量和放置。测量步骤运行传递给Layout可组合项的 measure lambda,LayoutModifier接口的MeasureScope.measure方法,等等。放置步骤运行layout函数的放置块,Modifier.offset { … }的 lambda 块,等等。
在每个步骤中读取的状态会影响布局以及可能的绘制阶段。当状态值更改时,Compose UI 会调度布局阶段。如果大小或位置已更改,它还会运行绘制阶段。
更精确地说,测量步骤和放置步骤具有独立的重启范围,这意味着放置步骤中的状态读取不会重新调用之前的测量步骤。但是,这两个步骤通常是交织在一起的,因此放置步骤中的状态读取可能会影响属于测量步骤的其他重启范围。
var offsetX by remember { mutableStateOf(8.dp) } Text( text = "Hello", modifier = Modifier.offset { // The `offsetX` state is read in the placement step // of the layout phase when the offset is calculated. // Changes in `offsetX` restart the layout. IntOffset(offsetX.roundToPx(), 0) } )
阶段 3:绘制
绘制代码期间的状态读取会影响绘制阶段。常见的示例包括Canvas()、Modifier.drawBehind和Modifier.drawWithContent。当状态值发生变化时,Compose UI 只运行绘制阶段。
var color by remember { mutableStateOf(Color.Red) } Canvas(modifier = modifier) { // The `color` state is read in the drawing phase // when the canvas is rendered. // Changes in `color` restart the drawing. drawRect(color) }

优化状态读取
由于 Compose 执行本地化状态读取跟踪,我们可以通过在适当的阶段读取每个状态来最大限度地减少执行的工作量。
让我们来看一个例子。这里我们有一个Image(),它使用 offset 修饰符来偏移其最终布局位置,从而在用户滚动时产生视差效果。
Box { val listState = rememberLazyListState() Image( // ... // Non-optimal implementation! Modifier.offset( with(LocalDensity.current) { // State read of firstVisibleItemScrollOffset in composition (listState.firstVisibleItemScrollOffset / 2).toDp() } ) ) LazyColumn(state = listState) { // ... } }
这段代码有效,但会导致性能不佳。按照编写方式,代码读取firstVisibleItemScrollOffset状态的值并将其传递给Modifier.offset(offset: Dp)函数。当用户滚动时,firstVisibleItemScrollOffset值将发生变化。众所周知,Compose 会跟踪任何状态读取,以便它可以重启(重新调用)读取代码,在本例中是Box的内容。
这是一个在**组合**阶段读取状态的示例。这并非一定是坏事,事实上,它是重新组合的基础,允许数据更改发出新的 UI。
但是,在本例中,它效率不高,因为每次滚动事件都会导致整个可组合内容重新评估,然后进行测量、布局和最终绘制。我们甚至在**显示内容**没有改变,只有**显示位置**改变的情况下,也在每次滚动时触发 Compose 阶段。我们可以优化状态读取,使其仅重新触发布局阶段。
offset 修饰符还有另一个版本可用:Modifier.offset(offset: Density.() -> IntOffset)。
此版本采用 lambda 参数,其中生成的偏移量由 lambda 块返回。让我们更新我们的代码以使用它。
Box { val listState = rememberLazyListState() Image( // ... Modifier.offset { // State read of firstVisibleItemScrollOffset in Layout IntOffset(x = 0, y = listState.firstVisibleItemScrollOffset / 2) } ) LazyColumn(state = listState) { // ... } }
为什么这更高效呢?我们提供给修饰符的 lambda 块在**布局**阶段(具体来说,在布局阶段的放置步骤期间)被调用,这意味着我们的firstVisibleItemScrollOffset状态不再在组合期间读取。因为 Compose 会跟踪何时读取状态,所以此更改意味着如果firstVisibleItemScrollOffset值发生更改,Compose 只需重启布局和绘制阶段。
此示例依赖于不同的 offset 修饰符才能优化生成的代码,但总体思路是正确的:尝试将状态读取定位到尽可能低的阶段,使 Compose 能够执行最少的工作量。
当然,通常绝对有必要在组合阶段读取状态。即便如此,在某些情况下,我们也可以通过过滤状态更改来最大限度地减少重新组合的数量。有关此方面的更多信息,请参阅derivedStateOf:将一个或多个状态对象转换为另一个状态。
重新组合循环(循环阶段依赖)
前面我们提到 Compose 的阶段总是按相同的顺序调用,并且在同一帧中无法向后移动。但是,这并不会阻止应用程序在不同帧之间进入组合循环。考虑这个例子。
Box { var imageHeightPx by remember { mutableStateOf(0) } Image( painter = painterResource(R.drawable.rectangle), contentDescription = "I'm above the text", modifier = Modifier .fillMaxWidth() .onSizeChanged { size -> // Don't do this imageHeightPx = size.height } ) Text( text = "I'm below the image", modifier = Modifier.padding( top = with(LocalDensity.current) { imageHeightPx.toDp() } ) ) }
在这里,我们(糟糕地)实现了一个垂直列,顶部是图像,底部是文本。我们使用Modifier.onSizeChanged()来了解图像的已解析大小,然后在文本上使用Modifier.padding()将其向下移动。从Px到Dp的非自然转换已经表明代码存在一些问题。
此示例的问题在于我们在一帧内无法达到“最终”布局。代码依赖于多帧的发生,这会执行不必要的工作,并导致 UI 对用户在屏幕上跳动。
让我们逐步完成每一帧以查看发生了什么。
在第一帧的组合阶段,imageHeightPx的值为 0,文本提供Modifier.padding(top = 0)。然后,布局阶段随之而来,并调用onSizeChanged修饰符的回调。这是imageHeightPx更新为图像实际高度的时候。Compose 安排下一帧的重新组合。在绘制阶段,文本以 0 的填充渲染,因为值更改尚未反映。
然后,Compose 开始由imageHeightPx的值更改安排的第二帧。在 Box 内容块中读取状态,并在组合阶段调用它。这次,文本提供了与图像高度匹配的填充。在布局阶段,代码确实再次设置了imageHeightPx的值,但由于值保持不变,因此不会安排重新组合。
最后,我们在文本上获得了所需的填充,但是花费额外的帧将填充值传递回不同的阶段效率不高,并且会导致生成具有重叠内容的帧。

此示例可能看起来很牵强,但请注意这种通用模式。
Modifier.onSizeChanged()、onGloballyPositioned()或其他一些布局操作。- 更新某些状态
- 将该状态用作布局修饰符(
padding()、height()或类似修饰符)的输入 - 可能重复
上面示例的解决方法是使用正确的布局原语。上面的示例可以使用简单的Column()实现,但您可能拥有更复杂的示例,需要自定义内容,这将需要编写自定义布局。有关更多信息,请参阅自定义布局指南。
这里的一般原则是为应该针对彼此进行测量和放置的多个 UI 元素拥有单个事实来源。使用正确的布局原语或创建自定义布局意味着最小的共享父级充当事实来源,可以协调多个元素之间的关系。引入动态状态会破坏此原则。
为您推荐
- 注意:当 JavaScript 关闭时,将显示链接文本。
- 状态和 Jetpack Compose
- 列表和网格
- Jetpack Compose 的 Kotlin