
离线优先应用是指能够脱离互联网执行其所有核心功能,或其核心功能的关键子集的应用。也就是说,它可以在离线状态下执行其部分或全部业务逻辑。
构建离线优先应用需要从数据层开始考虑,数据层提供对应用数据和业务逻辑的访问。应用可能需要不时地从设备外部源刷新此数据。在此过程中,它可能需要调用网络资源以保持最新状态。
网络可用性并非总能得到保证。设备通常会出现网络连接不稳定或缓慢的情况。用户可能会遇到以下情况:
- 互联网带宽有限
- 暂时性连接中断,例如在电梯或隧道中。
- 偶尔的数据访问。例如,仅支持 WLAN 的平板电脑。
无论原因如何,应用在这些情况下通常都能正常运行。为确保您的应用在离线状态下正常运行,它应能够执行以下操作:
- 在没有可靠网络连接的情况下仍可使用。
- 立即向用户显示本地数据,而不是等待第一次网络调用完成或失败。
- 以考虑电池和数据使用情况的方式获取数据。例如,仅在最佳条件下(例如充电时或连接 WLAN 时)请求数据获取。
能够满足上述条件的应用通常称为离线优先应用。
设计离线优先应用
设计离线优先应用时,您应该从数据层开始,以及可以对应用数据执行的两个主要操作:
- 读取:检索数据供应用的其他部分使用,例如向用户显示信息。
- 写入:持久保存用户输入以便稍后检索。
数据层中的代码库负责合并数据源以提供应用数据。在离线优先应用中,必须至少有一个数据源无需网络访问即可执行其最关键的任务。其中一项关键任务是读取数据。
在离线优先应用中建模数据
离线优先应用对于每个使用网络资源的代码库至少有 2 个数据源:
- 本地数据源
- 网络数据源
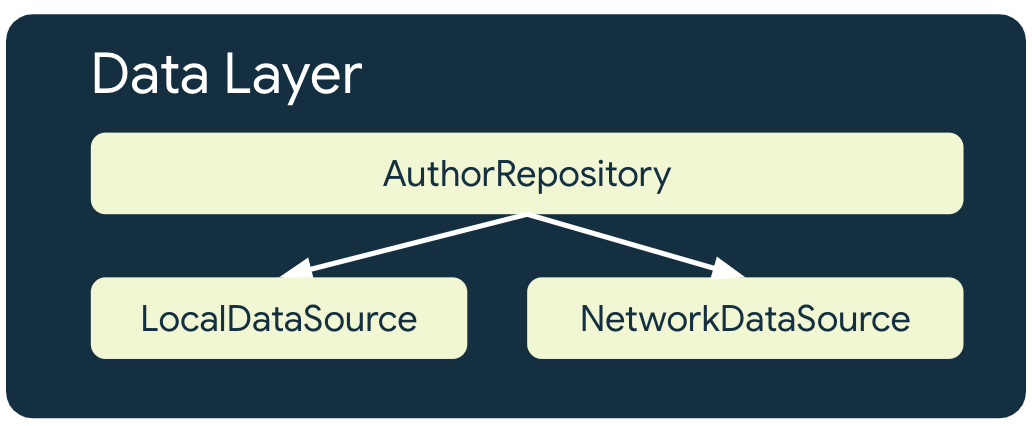
本地数据源
本地数据源是应用规范的单一可信来源。它应是应用更高层级读取的任何数据的唯一来源。这可确保连接状态之间的数据一致性。本地数据源通常由持久保存到磁盘的存储提供支持。持久保存数据到磁盘的一些常见方式如下:
- 结构化数据源,例如像 Room 这样的关系型数据库。
- 非结构化数据源。例如,带有 Datastore 的协议缓冲区。
- 简单文件
网络数据源
网络数据源是应用的实际状态。本地数据源最多与网络数据源同步。它也可能滞后于网络数据源,在这种情况下,应用在重新上线时需要进行更新。反之,网络数据源可能会滞后于本地数据源,直到连接恢复时应用才能更新它。应用的数据域层和界面层绝不应直接与网络层联络。托管代码库的责任是与其通信,并使用它来更新本地数据源。
公开资源
本地和网络数据源在应用读写方式上可能存在根本差异。查询本地数据源可以快速灵活,例如使用 SQL 查询时。相反,网络数据源可能很慢且受限,例如通过 ID 增量访问 RESTful 资源时。因此,每个数据源通常需要其提供的数据的自己的表示形式。因此,本地数据源和网络数据源可能拥有自己的模型。
下面的目录结构将此概念可视化。AuthorEntity 是从应用本地数据库读取的作者的表示形式,而 NetworkAuthor 是通过网络序列化的作者的表示形式
data/
├─ local/
│ ├─ entities/
│ │ ├─ AuthorEntity
│ ├─ dao/
│ ├─ NiADatabase
├─ network/
│ ├─ NiANetwork
│ ├─ models/
│ │ ├─ NetworkAuthor
├─ model/
│ ├─ Author
├─ repository/
AuthorEntity 和 NetworkAuthor 的详细信息如下:
/**
* Network representation of [Author]
*/
@Serializable
data class NetworkAuthor(
val id: String,
val name: String,
val imageUrl: String,
val twitter: String,
val mediumPage: String,
val bio: String,
)
/**
* Defines an author for either an [EpisodeEntity] or [NewsResourceEntity].
* It has a many-to-many relationship with both entities
*/
@Entity(tableName = "authors")
data class AuthorEntity(
@PrimaryKey
val id: String,
val name: String,
@ColumnInfo(name = "image_url")
val imageUrl: String,
@ColumnInfo(defaultValue = "")
val twitter: String,
@ColumnInfo(name = "medium_page", defaultValue = "")
val mediumPage: String,
@ColumnInfo(defaultValue = "")
val bio: String,
)
最佳实践是将 AuthorEntity 和 NetworkAuthor 保留在数据层内部,并公开第三种类型供外部层使用。这可以保护外部层不受本地和网络数据源的细微更改的影响,这些更改不会从根本上改变应用的行为。以下代码段演示了这一点:
/**
* External data layer representation of a "Now in Android" Author
*/
data class Author(
val id: String,
val name: String,
val imageUrl: String,
val twitter: String,
val mediumPage: String,
val bio: String,
)
然后,网络模型可以定义一个扩展方法以将其转换为本地模型,本地模型也类似地有一个将其转换为外部表示的方法,如下所示:
/**
* Converts the network model to the local model for persisting
* by the local data source
*/
fun NetworkAuthor.asEntity() = AuthorEntity(
id = id,
name = name,
imageUrl = imageUrl,
twitter = twitter,
mediumPage = mediumPage,
bio = bio,
)
/**
* Converts the local model to the external model for use
* by layers external to the data layer
*/
fun AuthorEntity.asExternalModel() = Author(
id = id,
name = name,
imageUrl = imageUrl,
twitter = twitter,
mediumPage = mediumPage,
bio = bio,
)
读取
读取是离线优先应用中对应用数据的基本操作。因此,您必须确保您的应用可以读取数据,并且只要有新数据可用,应用就可以显示它。能够做到这一点的应用是响应式应用,因为它们使用可观察类型公开读取 API。
在下面的代码段中,OfflineFirstTopicRepository 为其所有读取 API 返回 Flows。这使其能够在从网络数据源接收到更新时更新其读取器。换句话说,当其本地数据源失效时,它允许 OfflineFirstTopicRepository 推送更改。因此,OfflineFirstTopicRepository 的每个读取器都必须准备好处理当应用的蜂窝网络连接恢复时可能触发的数据更改。此外,OfflineFirstTopicRepository 直接从本地数据源读取数据。它只能通过首先更新其本地数据源来通知其读取器数据更改。
class OfflineFirstTopicsRepository(
private val topicDao: TopicDao,
private val network: NiaNetworkDataSource,
) : TopicsRepository {
override fun getTopicsStream(): Flow<List<Topic>> =
topicDao.getTopicEntitiesStream()
.map { it.map(TopicEntity::asExternalModel) }
}
错误处理策略
在离线优先应用中,根据可能发生错误的数据源,有独特的错误处理方式。以下小节概述了这些策略。
本地数据源
从本地数据源读取时发生错误的情况应该很少见。为保护读取器免受错误影响,请对读取器正在从中收集数据的 Flows 使用 catch 运算符。
在 ViewModel 中使用 catch 运算符如下所示:
class AuthorViewModel(
authorsRepository: AuthorsRepository,
...
) : ViewModel() {
private val authorId: String = ...
// Observe author information
private val authorStream: Flow<Author> =
authorsRepository.getAuthorStream(
id = authorId
)
.catch { emit(Author.empty()) }
}
网络数据源
如果从网络数据源读取数据时发生错误,应用将需要采用启发式方法来重试获取数据。常见的启发式方法包括:
指数退避
在指数退避中,应用会以递增的时间间隔不断尝试从网络数据源读取数据,直到成功,或者其他条件指示它应该停止。
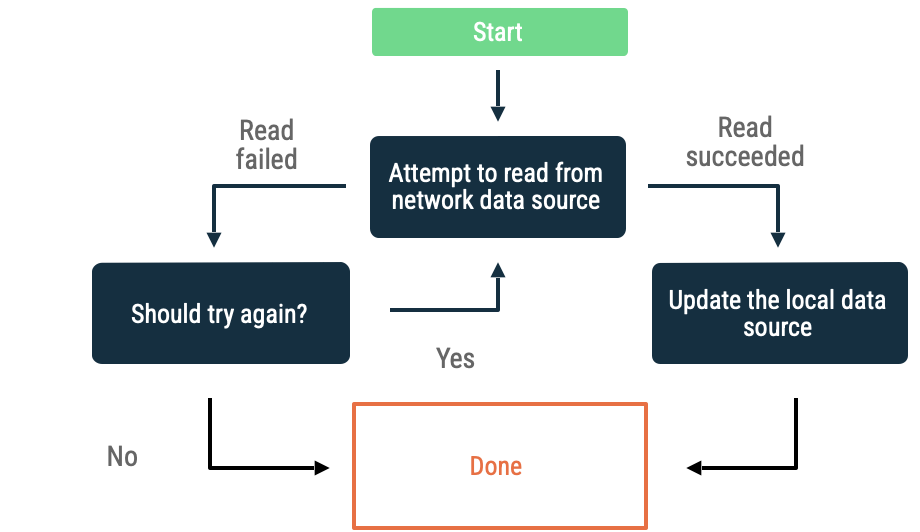
评估应用是否应继续退避的条件包括:
- 网络数据源指示的错误类型。例如,您应该重试返回指示缺少连接错误的网络调用。相反,您不应在获得适当凭据之前重试未经授权的 HTTP 请求。
- 最大允许重试次数。
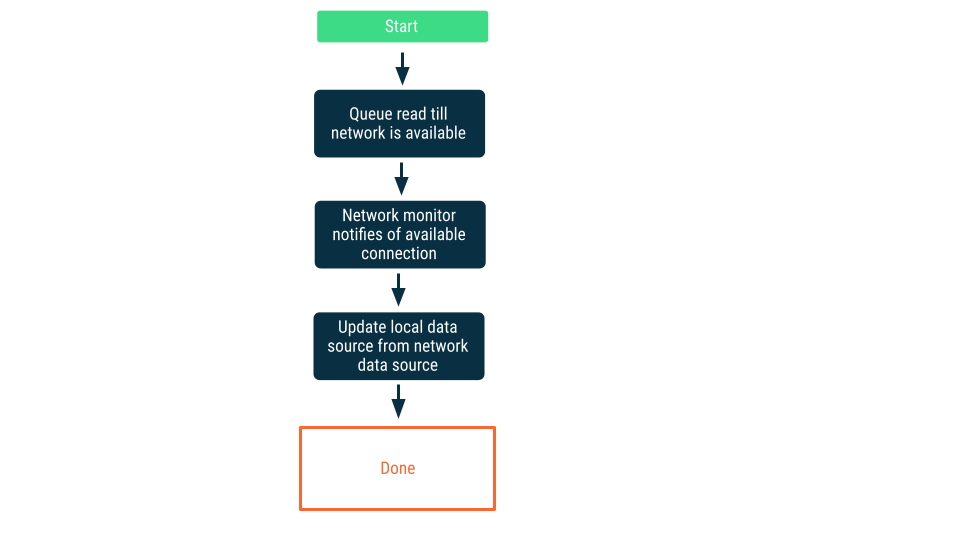
网络连接监控
在这种方法中,读取请求会被排队,直到应用确定可以连接到网络数据源。一旦建立连接,读取请求就会出队,数据被读取并更新本地数据源。在 Android 上,此队列可以使用 Room 数据库维护,并使用 WorkManager 作为持久性工作耗尽。
写入
虽然在离线优先应用中读取数据的推荐方式是使用可观察类型,但写入 API 的对应方式是异步 API,例如 suspend 函数。这可以避免阻塞界面线程,并有助于错误处理,因为离线优先应用中的写入在跨越网络边界时可能会失败。
interface UserDataRepository {
/**
* Updates the bookmarked status for a news resource
*/
suspend fun updateNewsResourceBookmark(newsResourceId: String, bookmarked: Boolean)
}
在上面的代码段中,选择的异步 API 是协程,因为上述方法会挂起。
写入策略
在离线优先应用中写入数据时,有三种策略需要考虑。您选择哪种策略取决于要写入的数据类型和应用的要求:
仅限在线写入
尝试跨网络边界写入数据。如果成功,则更新本地数据源;否则,抛出异常并由调用方适当响应。
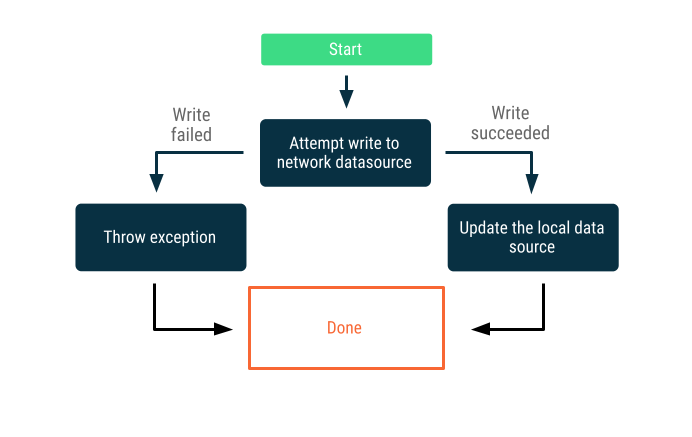
此策略通常用于必须近乎实时在线发生的写入事务。例如,银行转账。由于写入可能会失败,因此通常需要告知用户写入失败,或者首先阻止用户尝试写入数据。在这些情况下可以采用的一些策略可能包括:
- 如果应用需要互联网访问才能写入数据,它可能会选择不向用户显示允许用户写入数据的界面,或者至少禁用它。
- 您可以使用用户无法关闭的弹出消息或短暂提示来通知用户他们处于离线状态。
排队写入
当您有要写入的对象时,将其插入队列。当应用重新上线时,继续以指数退避的方式耗尽队列。在 Android 上,清空离线队列是持久性工作,通常委托给 WorkManager。
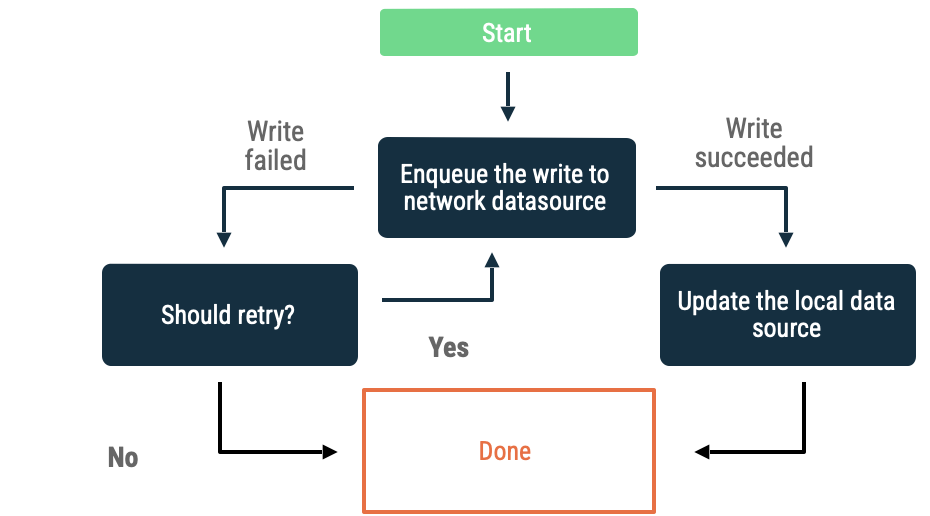
如果满足以下条件,此方法是一个不错的选择:
- 数据不一定非要写入网络。
- 事务不具有时效性。
- 用户不一定需要知道操作是否失败。
此方法的用例包括分析事件和日志记录。
延迟写入
先写入本地数据源,然后将写入排队,以便在最早方便时通知网络。这并非微不足道,因为当应用重新上线时,网络和本地数据源之间可能会发生冲突。关于冲突解决的下一节将提供更多详细信息。
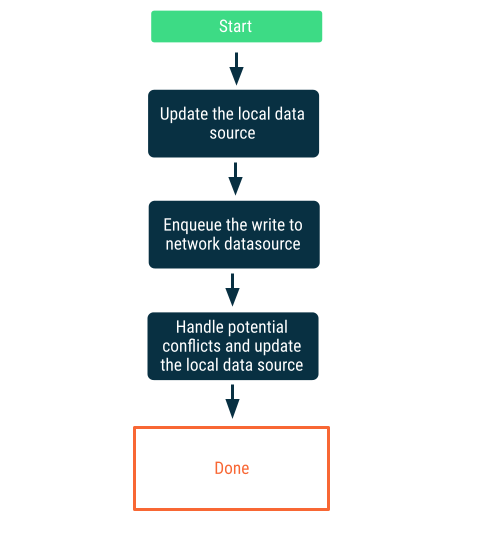
当数据对应用至关重要时,此方法是正确的选择。例如,在离线优先的待办事项列表应用中,用户离线添加的任何任务都必须存储在本地,以避免数据丢失的风险。
同步和冲突解决
当离线优先应用恢复连接时,它需要将其本地数据源中的数据与网络数据源中的数据进行协调。此过程称为同步。应用与其网络数据源同步主要有两种方式:
- 拉取式同步
- 推送式同步
拉取式同步
在拉取式同步中,应用按需连接网络以读取最新的应用数据。此方法的常见启发式方法是基于导航的,即应用仅在将数据呈现给用户之前获取数据。
当应用预期网络连接中断时间较短到中等时,此方法效果最佳。这是因为数据刷新是机会性的,长时间没有连接会增加用户尝试访问带有陈旧或空缓存的应用目标的可能性。
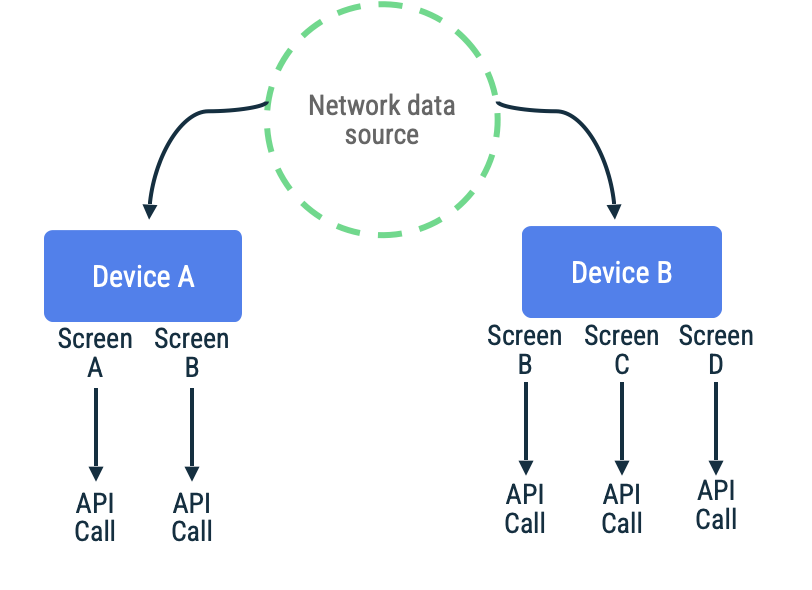
考虑一个应用,其中使用页面令牌来为特定屏幕的无限滚动列表获取项目。该实现可能会延迟连接网络,将数据持久化到本地数据源,然后从本地数据源读取以向用户呈现信息。在没有网络连接的情况下,代码库可能仅从本地数据源请求数据。这是 Jetpack Paging 库及其 RemoteMediator API 使用的模式。
class FeedRepository(...) {
fun feedPagingSource(): PagingSource<FeedItem> { ... }
}
class FeedViewModel(
private val repository: FeedRepository
) : ViewModel() {
private val pager = Pager(
config = PagingConfig(
pageSize = NETWORK_PAGE_SIZE,
enablePlaceholders = false
),
remoteMediator = FeedRemoteMediator(...),
pagingSourceFactory = feedRepository::feedPagingSource
)
val feedPagingData = pager.flow
}
拉取式同步的优缺点总结在下表中:
| 优点 | 缺点 |
|---|---|
| 相对容易实现。 | 容易导致大量数据使用。这是因为重复访问导航目标会触发不必要的未更改信息重新获取。您可以通过适当的缓存来缓解这种情况。这可以在界面层使用 cachedIn 运算符完成,或者在网络层使用 HTTP 缓存完成。 |
| 不需要的数据永远不会被获取。 | 与关系型数据配合使用时扩展性不佳,因为拉取的模型需要自给自足。如果正在同步的模型依赖于其他要获取的模型来填充自身,则前面提到的数据大量使用问题将变得更加突出。此外,它可能会导致父模型代码库与嵌套模型代码库之间存在依赖关系。 |
推送式同步
在推送式同步中,本地数据源会尽其所能模拟网络数据源的副本集。它会在首次启动时主动获取适量数据以设定基准,之后则依靠服务器通知在其数据陈旧时提醒它。
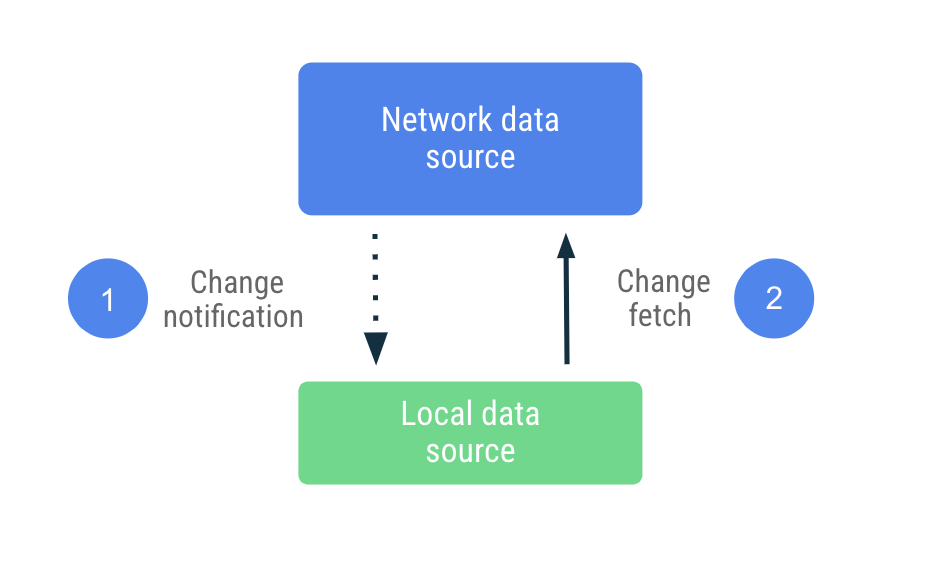
收到陈旧通知后,应用会连接网络,仅更新标记为陈旧的数据。此工作委托给代码库,后者会连接网络数据源,并将获取的数据持久保存到本地数据源。由于代码库使用可观察类型公开其数据,因此读取器将收到任何更改的通知。
class UserDataRepository(...) {
suspend fun synchronize() {
val userData = networkDataSource.fetchUserData()
localDataSource.saveUserData(userData)
}
}
在这种方法中,应用对网络数据源的依赖性大大降低,并且可以在没有网络的情况下长时间工作。它在离线时提供读写访问,因为它假定在本地拥有来自网络数据源的最新信息。
推送式同步的优缺点总结在下表中:
| 优点 | 缺点 |
|---|---|
| 应用可以无限期保持离线状态。 | 用于冲突解决的版本数据并非易事。 |
| 数据使用量最少。应用仅获取已更改的数据。 | 您需要在同步过程中考虑写入问题。 |
| 适用于关系型数据。每个代码库仅负责为其支持的模型获取数据。 | 网络数据源需要支持同步。 |
混合同步
有些应用采用混合方法,根据数据是基于拉取还是基于推送进行同步。例如,由于动态更新频繁,社交媒体应用可能会按需使用拉取式同步来获取用户的关注动态。同一应用可能会选择对已登录用户的数据(包括其用户名、个人资料图片等)使用推送式同步。
最终,离线优先同步的选择取决于产品要求和可用的技术基础设施。
冲突解决
如果应用在离线时在本地写入的数据与网络数据源不一致,则表示发生了冲突,您必须在同步发生之前解决该冲突。
冲突解决通常需要版本控制。应用需要进行一些记录,以跟踪更改发生的时间。这使得它能够将元数据传递给网络数据源。然后,网络数据源负责提供绝对的单一可信来源。有多种冲突解决策略需要考虑,具体取决于应用的需求。对于移动应用,一种常见的方法是“最后写入获胜”。
最后写入获胜
在这种方法中,设备将其写入网络的数据附加时间戳元数据。当网络数据源收到这些数据时,它会丢弃任何比其当前状态更旧的数据,同时接受比其当前状态更新的数据。
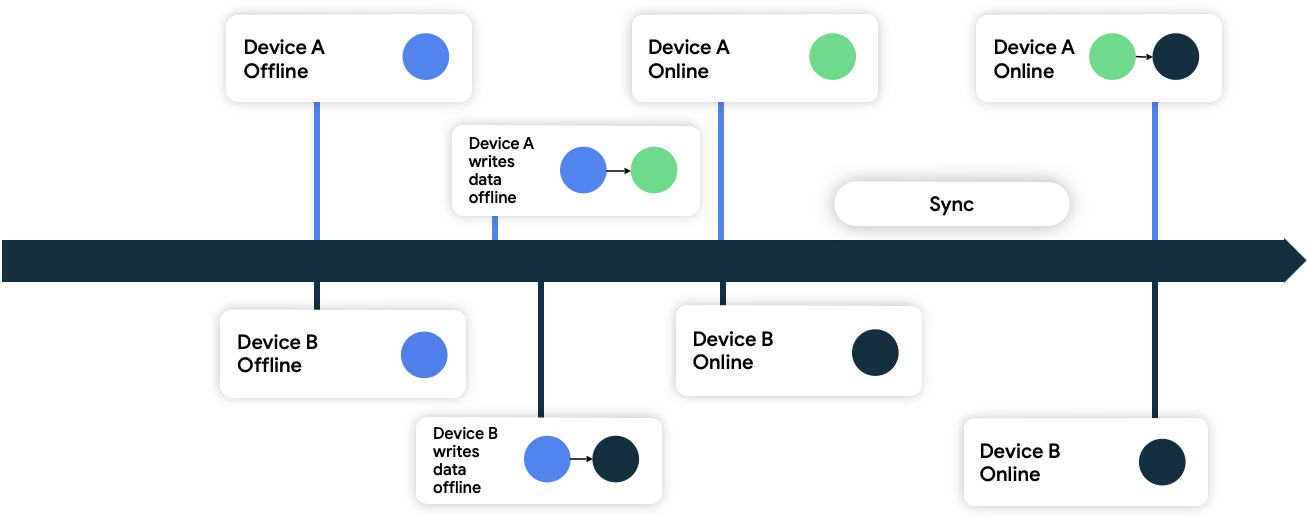
在上述情况中,两台设备都处于离线状态,并且最初与网络数据源同步。在离线状态下,它们都将数据写入本地并记录写入数据的时间。当它们都重新上线并与网络数据源同步时,网络通过持久化设备 B 的数据来解决冲突,因为它是在之后写入的数据。
离线优先应用中的 WorkManager
在上面介绍的读取和写入策略中,有两种常用的实用工具:
- 队列
- 读取:用于延迟读取,直到网络连接可用。
- 写入:用于延迟写入,直到网络连接可用,并重新排队写入以进行重试。
- 网络连接监控器
- 读取:用作当应用连接时以及进行同步时耗尽读取队列的信号
- 写入:用作当应用连接时以及进行同步时耗尽写入队列的信号
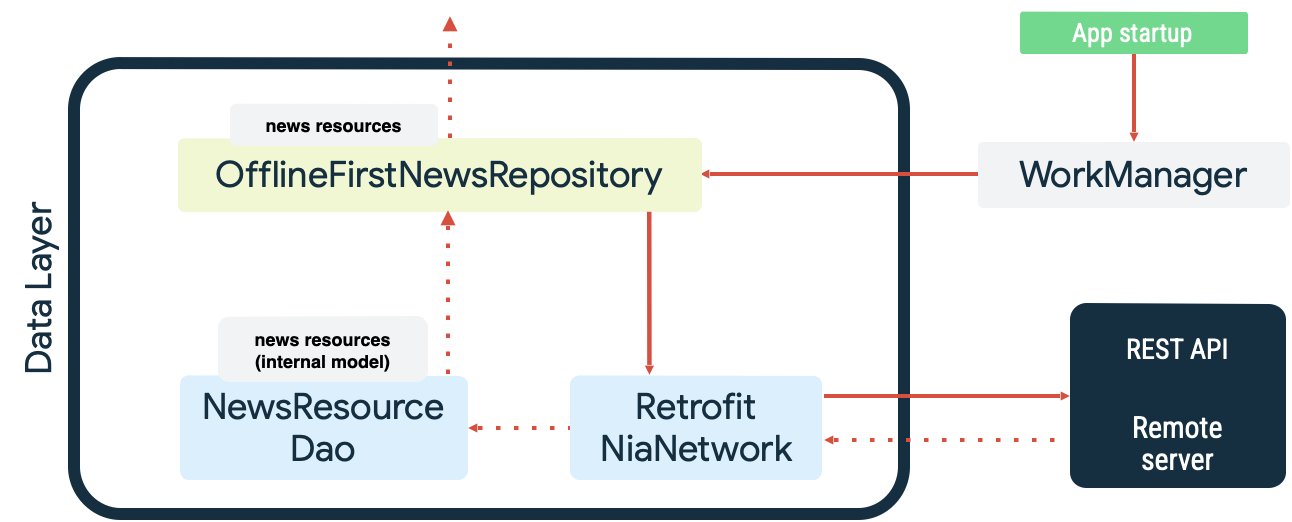
这两种情况都是 持久性工作的示例,而 WorkManager 在这方面表现出色。例如,在 Now in Android 示例应用中,WorkManager 在同步本地数据源时既用作读取队列,又用作网络监控器。在启动时,应用会执行以下操作:
- 将读取同步工作加入队列,以确保本地数据源和网络数据源之间保持一致性。
- 当应用在线时,清空读取同步队列并开始同步。
- 使用指数退避从网络数据源执行读取。
- 将读取结果持久保存到本地数据源,解决可能发生的任何冲突。
- 从本地数据源公开数据,供应用的其他层使用。
上图如下所示:
通过将同步工作指定为具有 KEEP ExistingWorkPolicy 的唯一工作来将同步工作加入 WorkManager 队列,如下所示:
class SyncInitializer : Initializer<Sync> {
override fun create(context: Context): Sync {
WorkManager.getInstance(context).apply {
// Queue sync on app startup and ensure only one
// sync worker runs at any time
enqueueUniqueWork(
SyncWorkName,
ExistingWorkPolicy.KEEP,
SyncWorker.startUpSyncWork()
)
}
return Sync
}
}
其中 SyncWorker.startupSyncWork() 定义如下:
/**
Create a WorkRequest to call the SyncWorker using a DelegatingWorker.
This allows for dependency injection into the SyncWorker in a different
module than the app module without having to create a custom WorkManager
configuration.
*/
fun startUpSyncWork() = OneTimeWorkRequestBuilder<DelegatingWorker>()
// Run sync as expedited work if the app is able to.
// If not, it runs as regular work.
.setExpedited(OutOfQuotaPolicy.RUN_AS_NON_EXPEDITED_WORK_REQUEST)
.setConstraints(SyncConstraints)
// Delegate to the SyncWorker.
.setInputData(SyncWorker::class.delegatedData())
.build()
val SyncConstraints
get() = Constraints.Builder()
.setRequiredNetworkType(NetworkType.CONNECTED)
.build()
具体来说,SyncConstraints 定义的 Constraints 要求 NetworkType 为 NetworkType.CONNECTED。也就是说,它会等到网络可用后才会运行。
一旦网络可用,Worker 会通过委托给相应的 Repository 实例来清空 SyncWorkName 指定的唯一工作队列。如果同步失败,doWork() 方法将返回 Result.retry()。WorkManager 将自动使用指数退避重试同步。否则,它将返回 Result.success() 以完成同步。
class SyncWorker(...) : CoroutineWorker(appContext, workerParams), Synchronizer {
override suspend fun doWork(): Result = withContext(ioDispatcher) {
// First sync the repositories in parallel
val syncedSuccessfully = awaitAll(
async { topicRepository.sync() },
async { authorsRepository.sync() },
async { newsRepository.sync() },
).all { it }
if (syncedSuccessfully) Result.success()
else Result.retry()
}
}
示例
以下 Google 示例演示了离线优先应用。前往探索它们,了解本指南的实际应用: