
WorkManager 允许您创建并排队一系列任务链,这些任务链指定了多个相互依赖的任务,并定义了它们的运行顺序。当您需要按特定顺序运行多个任务时,此功能特别有用。
要创建任务链,您可以使用 WorkManager.beginWith(OneTimeWorkRequest) 或 WorkManager.beginWith(List<OneTimeWorkRequest>),它们都返回一个 WorkContinuation 实例。
然后,可以使用 WorkContinuation 通过 then(OneTimeWorkRequest) 或 then(List<OneTimeWorkRequest>) 添加依赖的 OneTimeWorkRequest 实例。
每次调用 WorkContinuation.then(...) 都会返回一个 WorkContinuation 的新实例。如果您添加 OneTimeWorkRequest 实例的 List,这些请求可能会并行运行。
最后,您可以使用 WorkContinuation.enqueue() 方法将您的 WorkContinuation 链 enqueue() 到队列中。
我们来看一个例子。在此示例中,配置了 3 个不同的 Worker 作业以运行(可能并行)。这些 Worker 的结果随后会合并并传递给缓存 Worker 作业。最后,该作业的输出会传递给上传 Worker,上传 Worker 会将结果上传到远程服务器。
Kotlin
WorkManager.getInstance(myContext) // Candidates to run in parallel .beginWith(listOf(plantName1, plantName2, plantName3)) // Dependent work (only runs after all previous work in chain) .then(cache) .then(upload) // Call enqueue to kick things off .enqueue()
Java
WorkManager.getInstance(myContext) // Candidates to run in parallel .beginWith(Arrays.asList(plantName1, plantName2, plantName3)) // Dependent work (only runs after all previous work in chain) .then(cache) .then(upload) // Call enqueue to kick things off .enqueue();
输入合并器
当您链式连接 OneTimeWorkRequest 实例时,父工作请求的输出会作为输入传递给子请求。因此在上面的示例中,plantName1、plantName2 和 plantName3 的输出将作为输入传递给 cache 请求。
为了管理来自多个父工作请求的输入,WorkManager 使用 InputMerger。
WorkManager 提供了两种不同类型的 InputMerger
OverwritingInputMerger尝试将所有输入中的所有键添加到输出中。如果发生冲突,它会覆盖之前设置的键。ArrayCreatingInputMerger尝试合并输入,必要时创建数组。
如果您有更具体的用例,可以通过继承 InputMerger 来编写自己的实现。
OverwritingInputMerger
OverwritingInputMerger 是默认的合并方法。如果合并中存在键冲突,则键的最新值将覆盖结果输出数据中的任何先前版本。
例如,如果植物输入各自都有匹配其变量名称的键("plantName1"、"plantName2" 和 "plantName3"),那么传递给 cache worker 的数据将包含三个键值对。
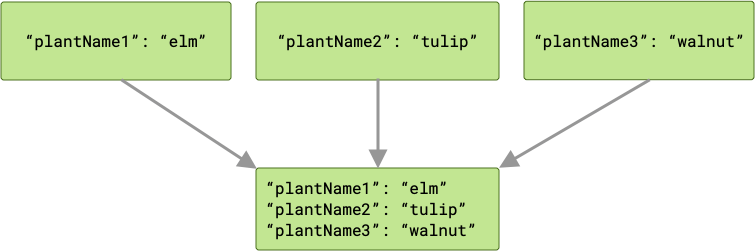
如果存在冲突,则最后完成的 worker “获胜”,其值将传递给 cache。
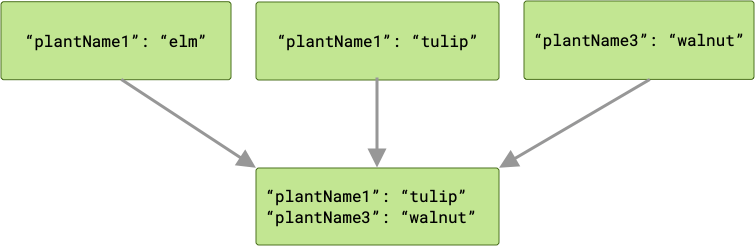
由于您的工作请求是并行运行的,因此不能保证它们的运行顺序。在上面的示例中,plantName1 的值可能是 "tulip" 或 "elm",具体取决于最后写入的值。如果您有可能发生键冲突并且需要在合并中保留所有输出数据,那么 ArrayCreatingInputMerger 可能是更好的选择。
ArrayCreatingInputMerger
对于上面的例子,鉴于我们希望保留所有植物名称 Worker 的输出,我们应该使用 ArrayCreatingInputMerger。
Kotlin
val cache: OneTimeWorkRequest = OneTimeWorkRequestBuilder<PlantWorker>() .setInputMerger(ArrayCreatingInputMerger::class) .setConstraints(constraints) .build()
Java
OneTimeWorkRequest cache = new OneTimeWorkRequest.Builder(PlantWorker.class) .setInputMerger(ArrayCreatingInputMerger.class) .setConstraints(constraints) .build();
ArrayCreatingInputMerger 将每个键与一个数组配对。如果每个键都是唯一的,则结果是一系列单元素数组。
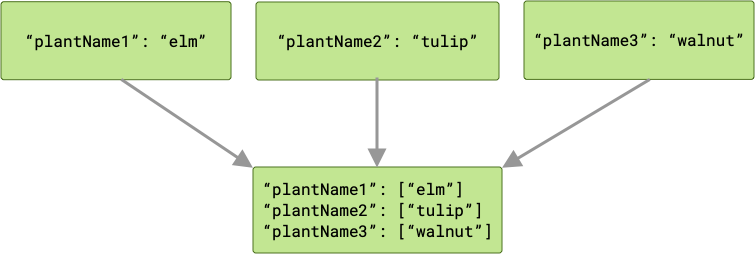
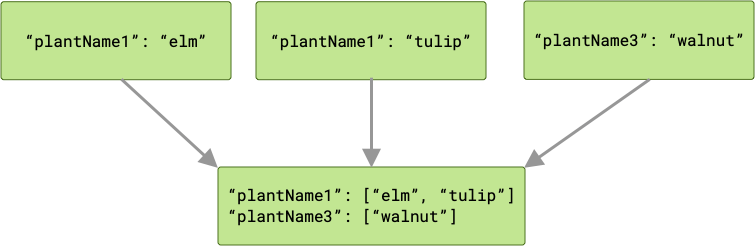
如果存在任何键冲突,则所有相应的值将分组到一个数组中。
任务链与工作状态
OneTimeWorkRequest 链会顺序执行,只要它们的工作成功完成(即它们返回 Result.success())。工作请求在运行时可能会失败或被取消,这对依赖的工作请求会产生下游影响。
当第一个 OneTimeWorkRequest 在工作请求链中入队时,所有后续工作请求都会被阻塞,直到第一个工作请求的工作完成。
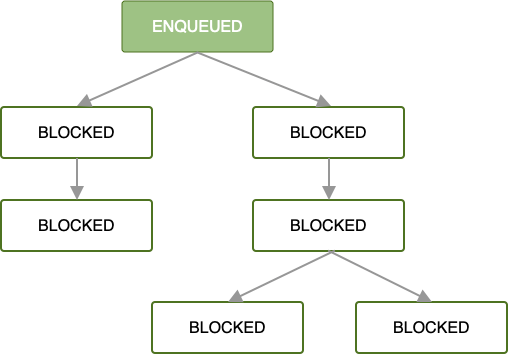
一旦入队并且所有工作限制都得到满足,第一个工作请求就开始运行。如果工作在根 OneTimeWorkRequest 或 List<OneTimeWorkRequest> 中成功完成(即它返回 Result.success()),则下一组依赖的工作请求将被入队。
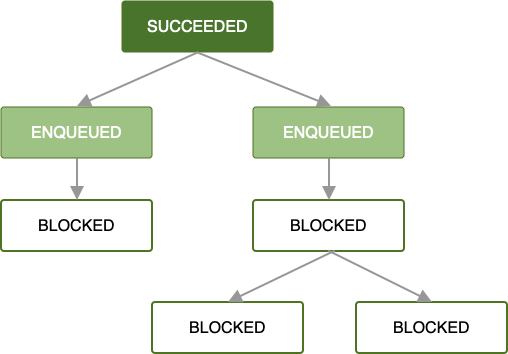
只要每个工作请求都成功完成,这种模式就会通过您工作请求链的其余部分传播,直到链中的所有工作都完成。虽然这是最简单且通常首选的情况,但错误状态同样重要。
当 worker 处理您的工作请求时发生错误,您可以根据 您定义的退避策略 重试该请求。重试链中作为一部分的请求意味着只有该请求将使用提供给它的输入数据进行重试。任何并行运行的工作都不会受到影响。
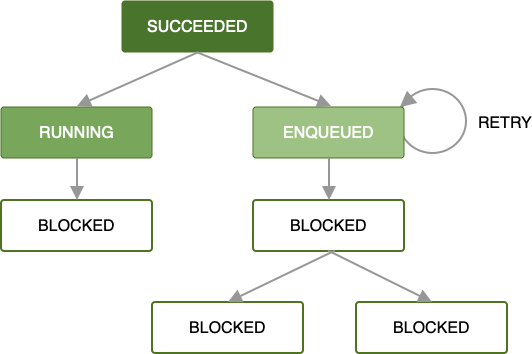
有关定义自定义重试策略的更多信息,请参阅 重试和退避策略。
如果重试策略未定义或已用尽,或者您以其他方式达到 OneTimeWorkRequest 返回 Result.failure() 的状态,则该工作请求和所有依赖的工作请求都将标记为 FAILED。
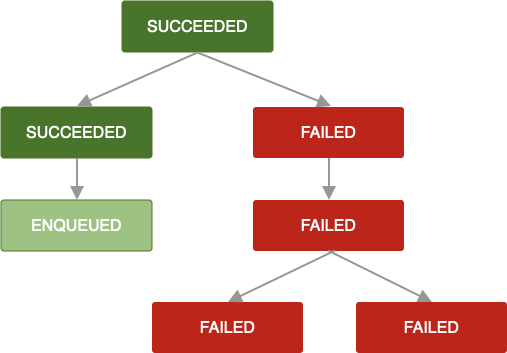
当 OneTimeWorkRequest 被取消时,也适用相同的逻辑。所有依赖的工作请求也会被标记为 CANCELLED,并且它们的工作将不会被执行。
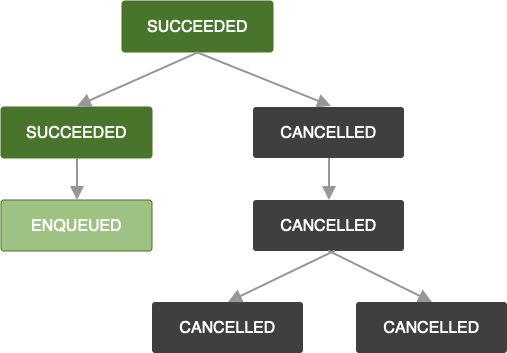
请注意,如果您将更多工作请求附加到已失败或已取消的工作请求链中,则您新附加的工作请求也将分别标记为 FAILED 或 CANCELLED。如果您想扩展现有链的工作,请参阅 ExistingWorkPolicy 中的 APPEND_OR_REPLACE。
在创建工作请求链时,依赖的工作请求应定义重试策略,以确保工作始终及时完成。失败的工作请求可能导致链不完整和/或意外状态。
有关更多信息,请参阅 取消和停止工作。