
1. 开始前的准备
在本 Codelab 中,您将学习如何使用 LiveData 构建器,在 Android 应用中将 Kotlin 协程与 LiveData 相结合。我们还将使用 协程异步 Flow,这是协程库中的一种类型,用于表示异步序列(或流)的值,来实现相同的功能。
您将从一个使用 Android Architecture Components 构建的现有应用开始,该应用使用 LiveData 从 Room 数据库获取对象列表,并在 RecyclerView 网格布局中显示它们。
以下是一些代码片段,可帮助您了解将要完成的任务。这是查询 Room 数据库的现有代码
val plants: LiveData<List<Plant>> = plantDao.getPlants()
LiveData 将使用 LiveData 构建器和包含额外排序逻辑的协程进行更新
val plants: LiveData<List<Plant>> = liveData<List<Plant>> {
val plantsLiveData = plantDao.getPlants()
val customSortOrder = plantsListSortOrderCache.getOrAwait()
emitSource(plantsLiveData.map { plantList -> plantList.applySort(customSortOrder) })
}
您还将使用 Flow 实现相同的逻辑
private val customSortFlow = plantsListSortOrderCache::getOrAwait.asFlow()
val plantsFlow: Flow<List<Plant>>
get() = plantDao.getPlantsFlow()
.combine(customSortFlow) { plants, sortOrder ->
plants.applySort(sortOrder)
}
.flowOn(defaultDispatcher)
.conflate()
前提条件
- 有使用 Architecture Components
ViewModel、LiveData、Repository和Room的经验。 - 有使用 Kotlin 语法的经验,包括扩展函数和 Lambda 表达式。
- 有使用 Kotlin 协程的经验。
- 对 Android 上的线程使用有基本了解,包括主线程、后台线程和回调。
您将执行的操作
- 将现有
LiveData转换为使用 Kotlin 协程友好的LiveData构建器。 - 在
LiveData构建器中添加逻辑。 - 使用
Flow进行异步操作。 - 结合
Flow并转换多个异步源。 - 使用
Flow控制并发。 - 了解如何在
LiveData和Flow之间进行选择。
您需要准备
- Android Studio Arctic Fox。此 Codelab 可能适用于其他版本,但某些内容可能会缺失或看起来不同。
如果您在完成此 Codelab 时遇到任何问题(代码错误、语法错误、措辞不清楚等),请通过 Codelab 左下角的“报告错误”链接报告问题。
2. 进行设置
下载代码
点击以下链接下载此 Codelab 的所有代码
... 或者使用以下命令从命令行克隆 GitHub 代码库
$ git clone https://github.com/googlecodelabs/kotlin-coroutines.git
本 Codelab 的代码位于 advanced-coroutines-codelab 目录中。
常见问题
3. 运行起始示例应用
首先,让我们看看起始示例应用的样子。按照以下说明在 Android Studio 中打开示例应用。
- 如果您下载了
kotlin-coroutineszip 文件,请解压该文件。 - 在 Android Studio 中打开
advanced-coroutines-codelab目录。 - 确保在配置下拉菜单中选中了
start。 - 点击运行
 按钮,然后选择模拟设备或连接您的 Android 设备。设备必须能够运行 Android Lollipop(最低支持的 SDK 为 21)。
按钮,然后选择模拟设备或连接您的 Android 设备。设备必须能够运行 Android Lollipop(最低支持的 SDK 为 21)。
应用首次运行时,会出现卡片列表,每张卡片都显示特定植物的名称和图片

每种 Plant 都有一个 growZoneNumber 属性,该属性表示植物最有可能茁壮成长的区域。用户可以点按过滤图标  在显示所有植物和显示特定生长区域(硬编码为区域 9)的植物之间切换。多按几次过滤按钮,看看实际效果。
在显示所有植物和显示特定生长区域(硬编码为区域 9)的植物之间切换。多按几次过滤按钮,看看实际效果。

架构概览
此应用使用 Architecture Components 将 MainActivity 和 PlantListFragment 中的 UI 代码与 PlantListViewModel 中的应用逻辑分离。PlantRepository 提供了 ViewModel 和 PlantDao 之间的桥梁,后者访问 Room 数据库以返回 Plant 对象列表。然后,UI 获取此植物列表,并在 RecyclerView 网格布局中显示它们。
在开始修改代码之前,让我们快速了解一下数据从数据库到 UI 的流向。以下是在 ViewModel 中加载植物列表的方式
PlantListViewModel.kt
val plants: LiveData<List<Plant>> = growZone.switchMap { growZone ->
if (growZone == NoGrowZone) {
plantRepository.plants
} else {
plantRepository.getPlantsWithGrowZone(growZone)
}
}
一个 GrowZone 是一个内联类,仅包含表示其区域的 Int。NoGrowZone 表示没有区域,仅用于过滤。
Plant.kt
inline class GrowZone(val number: Int)
val NoGrowZone = GrowZone(-1)
点按过滤按钮时,会切换 growZone。我们使用 switchMap 来确定要返回的植物列表。
以下是用于从数据库中获取植物数据的存储库和数据访问对象 (DAO) 的样子
PlantDao.kt
@Query("SELECT * FROM plants ORDER BY name")
fun getPlants(): LiveData<List<Plant>>
@Query("SELECT * FROM plants WHERE growZoneNumber = :growZoneNumber ORDER BY name")
fun getPlantsWithGrowZoneNumber(growZoneNumber: Int): LiveData<List<Plant>>
PlantRepository.kt
val plants = plantDao.getPlants()
fun getPlantsWithGrowZone(growZone: GrowZone) =
plantDao.getPlantsWithGrowZoneNumber(growZone.number)
虽然大部分代码修改都在 PlantListViewModel 和 PlantRepository 中,但花点时间熟悉项目结构是个好主意,重点关注植物数据如何通过从数据库到 Fragment 的各个层显示出来。在下一步中,我们将修改代码,使用 LiveData 构建器添加自定义排序。
4. 带有自定义排序的植物
植物列表当前按字母顺序显示,但我们希望更改此列表的顺序,首先列出某些植物,然后其余植物按字母顺序排列。这类似于购物应用在可供购买的商品列表顶部显示赞助结果。我们的产品团队希望能够在不发布新版本应用的情况下动态更改排序顺序,因此我们将首先从后端获取要排序的植物列表。
以下是应用进行自定义排序后的样子
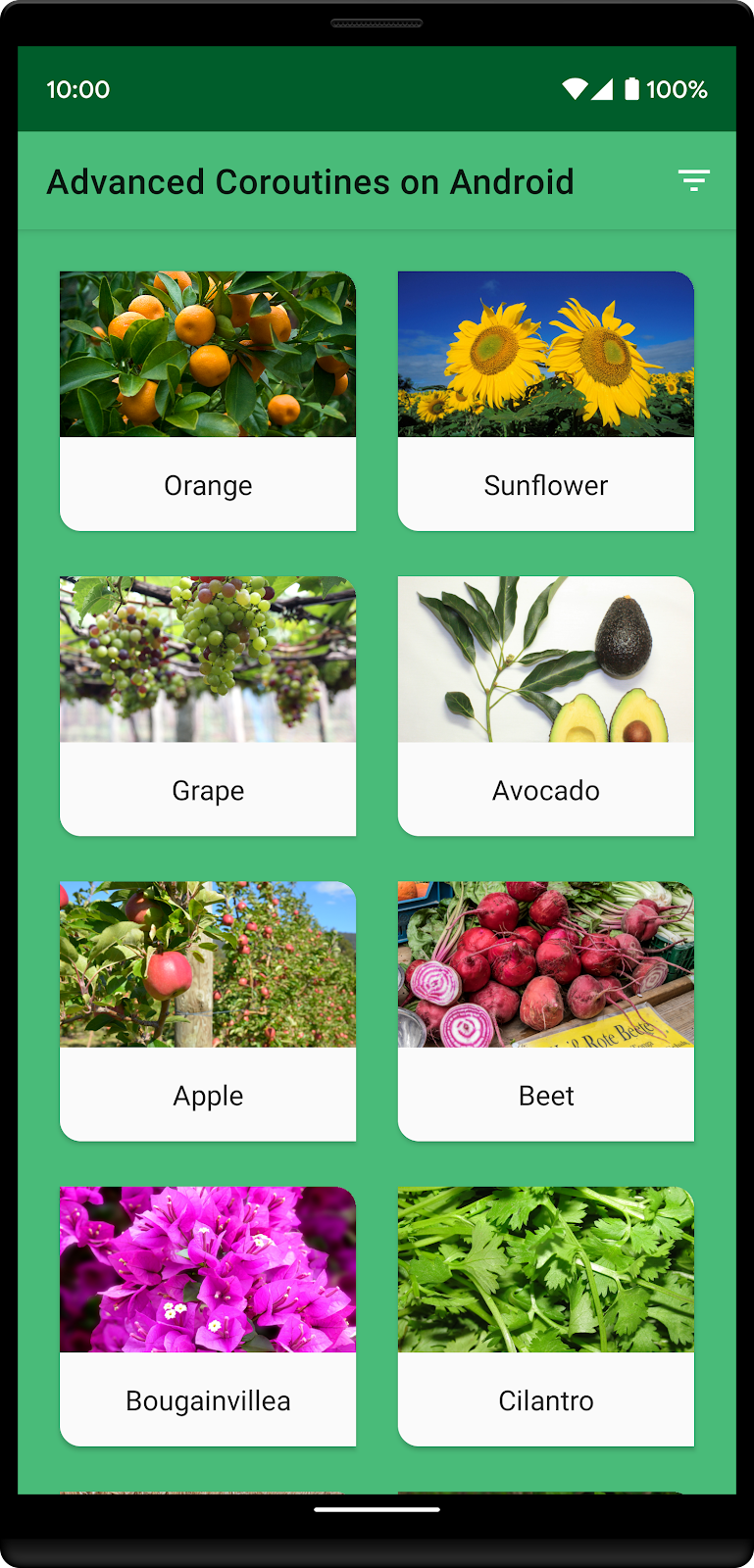
自定义排序列表包含这四种植物:橙、向日葵、葡萄和牛油果。请注意它们是如何首先出现在列表中的,然后是按字母顺序排列的其他植物。
现在,如果按下过滤按钮(并且只显示 GrowZone 9 的植物),向日葵会从列表中消失,因为它的 GrowZone 不是 9。自定义排序列表中的其他三种植物都在 GrowZone 9 中,所以它们会保留在列表顶部。在此列表中,唯一其他在 GrowZone 9 中的植物是番茄,它出现在列表的最后。
让我们开始编写代码来实现自定义排序。
5. 获取排序顺序
我们将首先编写一个 suspending 函数来从网络获取自定义排序顺序,然后将其缓存到内存中。
将以下内容添加到 PlantRepository
PlantRepository.kt
private var plantsListSortOrderCache =
CacheOnSuccess(onErrorFallback = { listOf<String>() }) {
plantService.customPlantSortOrder()
}
plantsListSortOrderCache 用作自定义排序顺序的内存缓存。如果发生网络错误,它将回退到空列表,以便我们的应用即使未获取排序顺序仍可显示数据。
此代码使用 sunflower 模块中提供的 CacheOnSuccess 实用类来处理缓存。通过抽象化实现此类缓存的详细信息,应用代码可以更加直观。由于 CacheOnSuccess 已经过良好测试,我们无需为存储库编写太多测试来确保其正确行为。在使用 kotlinx-coroutines 时,最好在代码中引入类似的高级抽象。
现在,让我们加入一些逻辑,将排序应用于植物列表。
将以下内容添加到 PlantRepository:
PlantRepository.kt
private fun List<Plant>.applySort(customSortOrder: List<String>): List<Plant> {
return sortedBy { plant ->
val positionForItem = customSortOrder.indexOf(plant.plantId).let { order ->
if (order > -1) order else Int.MAX_VALUE
}
ComparablePair(positionForItem, plant.name)
}
}
此扩展函数将重新排列列表,将 customSortOrder 中的 Plants 放在列表前面。
6. 使用 LiveData 构建逻辑
现在排序逻辑已到位,请使用下面的 LiveData 构建器 替换 plants 和 getPlantsWithGrowZone 的代码
PlantRepository.kt
val plants: LiveData<List<Plant>> = liveData<List<Plant>> {
val plantsLiveData = plantDao.getPlants()
val customSortOrder = plantsListSortOrderCache.getOrAwait()
emitSource(plantsLiveData.map {
plantList -> plantList.applySort(customSortOrder)
})
}
fun getPlantsWithGrowZone(growZone: GrowZone) = liveData {
val plantsGrowZoneLiveData = plantDao.getPlantsWithGrowZoneNumber(growZone.number)
val customSortOrder = plantsListSortOrderCache.getOrAwait()
emitSource(plantsGrowZoneLiveData.map { plantList ->
plantList.applySort(customSortOrder)
})
}
现在,如果您运行应用,应该会出现自定义排序的植物列表
LiveData 构建器允许我们异步计算值,因为 liveData 是由协程支持的。在这里,我们有一个 suspend 函数来从数据库获取 LiveData 植物列表,同时还调用一个 suspend 函数来获取自定义排序顺序。然后,我们结合这两个值来对植物列表进行排序并返回值,所有这些都在构建器中完成。
协程在被观察时开始执行,并在协程成功完成或数据库或网络调用失败时取消。
在下一步中,我们将使用 Transformation 探索 getPlantsWithGrowZone 的变体。
7. liveData: 修改值
我们现在将修改 PlantRepository,以便在处理每个值时实现暂停的 转换,从而学习如何在 LiveData 中构建复杂的异步转换。作为先决条件,让我们创建一个可在主线程上安全使用的排序算法版本。我们可以使用 withContext 仅针对 lambda 切换到另一个调度程序,然后恢复到我们开始时的调度程序。
将以下内容添加到 PlantRepository
PlantRepository.kt
@AnyThread
suspend fun List<Plant>.applyMainSafeSort(customSortOrder: List<String>) =
withContext(defaultDispatcher) {
this@applyMainSafeSort.applySort(customSortOrder)
}
然后,我们可以将这个新的主线程安全排序与 LiveData 构建器一起使用。更新代码块以使用 switchMap,它允许您在每次收到新值时指向一个新的 LiveData。
PlantRepository.kt
fun getPlantsWithGrowZone(growZone: GrowZone) =
plantDao.getPlantsWithGrowZoneNumber(growZone.number)
.switchMap { plantList ->
liveData {
val customSortOrder = plantsListSortOrderCache.getOrAwait()
emit(plantList.applyMainSafeSort(customSortOrder))
}
}
与之前版本相比,一旦从网络接收到自定义排序顺序,就可以将其与新的主线程安全的 applyMainSafeSort 一起使用。然后将此结果作为 getPlantsWithGrowZone 返回的新值发出到 switchMap 中。
与上面的 plants LiveData 类似,协程在被观察时开始执行,并在完成时或数据库或网络调用失败时终止。这里的区别在于,由于它被缓存了,在 map 中进行网络调用是安全的。
现在,我们来看看如何使用 Flow 实现这段代码,并比较它们的实现。
8. Flow 简介
我们将使用 kotlinx-coroutines 中的 Flow 构建相同的逻辑。在此之前,我们先了解一下什么是 flow 以及如何将其集成到您的应用中。
flow 是 Sequence 的异步版本,是一种其值是延迟生成的集合类型。与 sequence 一样,flow 在需要值时按需生成每个值,并且 flow 可以包含无限个值。
那么,Kotlin 为什么要引入一个新的 Flow 类型,它与常规的 sequence 有何不同?答案在于异步的魔力。Flow 包含对协程的全面支持。这意味着您可以使用协程构建、转换和使用 Flow。您还可以控制并发,这意味着使用 Flow 以声明方式协调多个协程的执行。
这开辟了许多令人兴奋的可能性。
Flow 可以以完全响应式编程风格使用。如果您以前使用过 RxJava 之类的库,Flow 提供了类似的功能。应用逻辑可以通过使用函数式运算符(例如 map、flatMapLatest、combine 等)转换 flow 来简洁地表达。
Flow 还支持大多数运算符上的 suspending 函数。这使您可以在 map 等运算符内部执行顺序异步任务。通过在 flow 内部使用挂起操作,代码通常比完全响应式风格中的等效代码更短、更易于阅读。
在本 Codelab 中,我们将探索使用这两种方法。
flow 如何运行
为了习惯 Flow 按需(或延迟)产生值的方式,请看以下 Flow 示例,它发出值 (1, 2, 3) 并在每个项目产生之前、期间和之后打印日志。
fun makeFlow() = flow {
println("sending first value")
emit(1)
println("first value collected, sending another value")
emit(2)
println("second value collected, sending a third value")
emit(3)
println("done")
}
scope.launch {
makeFlow().collect { value ->
println("got $value")
}
println("flow is completed")
}
如果您运行此代码,它会产生此输出
sending first value got 1 first value collected, sending another value got 2 second value collected, sending a third value got 3 done flow is completed
您可以看到执行是如何在 collect lambda 和 flow 构建器之间来回跳跃的。每当 flow 构建器调用 emit 时,它会 suspends 直到元素完全处理完毕。然后,当从 flow 中请求另一个值时,它会 resumes 从中断的地方继续执行,直到再次调用 emit。当 flow 构建器完成时,collect 现在可以完成,并且调用块会打印“flow is completed.”。
collect 的调用非常重要。Flow 使用像 collect 这样的 suspending 运算符,而不是公开 Iterator 接口,这样它总是知道何时被主动使用。更重要的是,它知道调用者何时不再需要任何值,以便它可以清理资源。
flow 何时运行
上面例子中的 Flow 在 collect 运算符运行时开始运行。调用 flow 构建器或其他 API 创建新的 Flow 不会执行任何工作。suspend 运算符 collect 在 Flow 中被称为终止运算符。kotlinx-coroutines 中还提供了其他 suspend 终止运算符,例如 toList、first 和 single,您也可以构建自己的终止运算符。
默认情况下,Flow 将执行:
- 每次应用终止运算符时(并且每个新的调用都独立于任何先前启动的调用)
- 直到它正在运行的协程被取消
- 当最后一个值已完全处理,并且已请求下一个值时
由于这些规则,Flow 可以参与结构化并发,并且从 Flow 启动长时间运行的协程是安全的。由于它们在调用者被取消时总是使用协程协作取消规则进行清理,因此 Flow 不会泄漏资源。
让我们修改上面的 flow,使用 take 运算符只查看前两个元素,然后收集两次。
scope.launch {
val repeatableFlow = makeFlow().take(2) // we only care about the first two elements
println("first collection")
repeatableFlow.collect()
println("collecting again")
repeatableFlow.collect()
println("second collection completed")
}
运行此代码,您将看到此输出
first collection sending first value first value collected, sending another value collecting again sending first value first value collected, sending another value second collection completed
每次调用 collect 时,flow lambda 都从顶部开始。如果 flow 执行了昂贵的操作(如进行网络请求),这一点很重要。另外,由于我们应用了 take(2) 运算符,flow 只会产生两个值。它在第二次调用 emit 后不会再次恢复 flow lambda,因此“second value collected...”这一行永远不会打印出来。
9. 使用 flow 进行异步操作
好的,Flow 像 Sequence 一样是惰性的,但它又是如何异步的呢?让我们来看一个异步序列的示例——观察数据库的更改。
在此示例中,我们需要协调在数据库线程池上生成的数据与驻留在另一个线程(例如主线程或 UI 线程)上的观察者。而且,由于我们将随着数据的更改重复发出结果,因此此场景非常适合异步序列模式。
想象一下,您负责编写 Room 对 Flow 的集成。如果您从 Room 中现有的 suspend 查询支持开始,您可能会编写类似以下代码
// This code is a simplified version of how Room implements flow
fun <T> createFlow(query: Query, tables: List<Tables>): Flow<T> = flow {
val changeTracker = tableChangeTracker(tables)
while(true) {
emit(suspendQuery(query))
changeTracker.suspendUntilChanged()
}
}
此代码依赖于两个虚构的 suspending 函数来生成一个 Flow
suspendQuery– 一个主线程安全函数,运行常规的Roomsuspend 查询suspendUntilChanged– 一个暂停协程直到某个表更改的函数
收集时,flow 最初会 emit 查询的第一个值。一旦处理了该值,flow 将恢复并调用 suspendUntilChanged,它会像其名称所示一样执行——暂停 flow 直到某个表更改。此时,系统中没有发生任何事情,直到某个表更改并且 flow 恢复。
当 flow 恢复时,它会执行另一个主线程安全查询,并 emits 结果。这个过程在一个无限循环中永远持续下去。
Flow 和结构化并发
等等——我们不想泄露工作!协程本身并不是非常昂贵,但它会反复唤醒自身以执行数据库查询。这是一个相当昂贵的泄露。
即使我们创建了一个无限循环,Flow 通过支持结构化并发来帮助我们。
消耗值或迭代 flow 的唯一方法是使用终止运算符。由于所有终止运算符都是 suspend 函数,因此工作受限于调用它们的 scope 的生命周期。当 scope 被取消时,flow 会使用常规的 协程协作取消规则 自动取消自身。因此,即使我们在 flow 构建器中编写了一个无限循环,由于结构化并发,我们可以安全地使用它而不会发生泄漏。
10. 使用 Flow 与 Room
在本步骤中,您将学习如何将 Flow 与 Room 结合使用,并将其连接到 UI。
此步骤对于 Flow 的许多用法来说很常见。以这种方式使用时,来自 Room 的 Flow 就像一个可观察的数据库查询,类似于 LiveData。
更新 Dao
首先,打开 PlantDao.kt,并添加两个返回 Flow<List<Plant>> 的新查询
PlantDao.kt
@Query("SELECT * from plants ORDER BY name")
fun getPlantsFlow(): Flow<List<Plant>>
@Query("SELECT * from plants WHERE growZoneNumber = :growZoneNumber ORDER BY name")
fun getPlantsWithGrowZoneNumberFlow(growZoneNumber: Int): Flow<List<Plant>>
请注意,除了返回类型之外,这些函数与 LiveData 版本相同。但是,我们将它们并排开发以进行比较。
通过指定 Flow 返回类型,Room 以以下特点执行查询
- 主线程安全 – 返回类型为
Flow的查询始终在Room执行器上运行,因此它们始终是主线程安全的。您无需在代码中执行任何操作即可使其在非主线程上运行。 - 观察更改 –
Room会自动观察更改并向 flow 发出新值。 - 异步序列 –
Flow会在每次更改时发出整个查询结果,并且不会引入任何缓冲区。如果您返回Flow<List<T>>,则 flow 会发出一个包含查询结果中所有行的List<T>。它将像序列一样执行 – 一次发出一个查询结果,并在被请求下一个结果之前暂停。 - 可取消 – 当收集这些 flow 的 scope 被取消时,
Room会取消观察此查询。
总而言之,这使得 Flow 成为从 UI 层观察数据库的优秀返回类型。
更新 repository
为了继续将新的返回值连接到 UI,打开 PlantRepository.kt,并添加以下代码
PlantRepository.kt
val plantsFlow: Flow<List<Plant>>
get() = plantDao.getPlantsFlow()
fun getPlantsWithGrowZoneFlow(growZoneNumber: GrowZone): Flow<List<Plant>> {
return plantDao.getPlantsWithGrowZoneNumberFlow(growZoneNumber.number)
}
目前,我们只是将 Flow 值传递给调用者。这与我们开始本 Codelab 时将 LiveData 传递给 ViewModel 的情况完全相同。
更新 ViewModel
在 PlantListViewModel.kt 中,让我们从简单开始,只公开 plantsFlow。我们稍后再回来,在接下来的几个步骤中向 flow 版本添加生长区域切换。
PlantListViewModel.kt
// add a new property to plantListViewModel
val plantsUsingFlow: LiveData<List<Plant>> = plantRepository.plantsFlow.asLiveData()
同样,我们将保留 LiveData 版本(val plants)以便在进行过程中进行比较。
由于我们希望在本 codelab 中在 UI 层保留 LiveData,我们将使用 asLiveData 扩展函数将我们的 Flow 转换为 LiveData。就像 LiveData 构建器一样,这会为生成的 LiveData 添加一个可配置的超时时间。这很好,因为它使我们不必在每次配置更改时(例如设备旋转)重新启动查询。
由于 flow 提供了主线程安全和取消的能力,您可以选择将 Flow 一直传递到 UI 层,而无需将其转换为 LiveData。但是,在本 Codelab 中,我们将继续在 UI 层使用 LiveData。
同样在 ViewModel 中,在 init 块中添加一个缓存更新。这一步目前是可选的,但是如果您清除了缓存并且不添加此调用,您将不会在应用中看到任何数据。
PlantListViewModel.kt
init {
clearGrowZoneNumber() // keep this
// fetch the full plant list
launchDataLoad { plantRepository.tryUpdateRecentPlantsCache() }
}
更新 Fragment
打开 PlantListFragment.kt,并将 subscribeUi 函数更改为指向我们新的 plantsUsingFlow LiveData。
PlantListFragment.kt
private fun subscribeUi(adapter: PlantAdapter) {
viewModel.plantsUsingFlow.observe(viewLifecycleOwner) { plants ->
adapter.submitList(plants)
}
}
使用 Flow 运行应用
如果您再次运行应用,您应该会看到您现在正在使用 Flow 加载数据!由于我们尚未实现 switchMap,因此过滤选项无效。
在下一步中,我们将介绍在 Flow 中转换数据。
11. 以声明方式组合 Flow
在此步骤中,您将把排序顺序应用于 plantsFlow。我们将使用 flow 的声明式 API 来实现。
通过使用像 map、combine 或 mapLatest 这样的转换,我们可以以声明的方式表达我们希望如何转换流中的每个元素。它甚至允许我们以声明的方式表达并发,这可以大大简化代码。在本节中,您将看到如何使用运算符来指示 Flow 启动两个协程并以声明的方式组合它们的结果。
首先,打开 PlantRepository.kt 并定义一个新的 private flow 称为 customSortFlow
PlantRepository.kt
private val customSortFlow = flow { emit(plantsListSortOrderCache.getOrAwait()) }
这将定义一个 Flow,当收集时,它将调用 getOrAwait 并 emit 排序顺序。
由于此 flow 只发出一个值,您也可以使用 asFlow 直接从 getOrAwait 函数构建它。
// Create a flow that calls a single function
private val customSortFlow = plantsListSortOrderCache::getOrAwait.asFlow()
这段代码创建了一个新的 Flow,它调用 getOrAwait 并将其结果作为其第一个也是唯一一个值发出。它通过使用 :: 引用 getOrAwait 方法并在生成的 Function 对象上调用 asFlow 来完成此操作。
这两个 flow 都做相同的事情,调用 getOrAwait 并在完成之前发出结果。
声明式地组合多个 flow
现在我们有了两个 flow,customSortFlow 和 plantsFlow,让我们以声明式的方式将它们组合起来!
将 combine 运算符添加到 plantsFlow
PlantRepository.kt
private val customSortFlow = plantsListSortOrderCache::getOrAwait.asFlow()
val plantsFlow: Flow<List<Plant>>
get() = plantDao.getPlantsFlow()
// When the result of customSortFlow is available,
// this will combine it with the latest value from
// the flow above. Thus, as long as both `plants`
// and `sortOrder` are have an initial value (their
// flow has emitted at least one value), any change
// to either `plants` or `sortOrder` will call
// `plants.applySort(sortOrder)`.
.combine(customSortFlow) { plants, sortOrder ->
plants.applySort(sortOrder)
}
combine 运算符将两个 flow 组合在一起。两个 flow 都将在自己的协程中运行,然后每当其中一个 flow 产生一个新值时,转换将使用来自任一个 flow 的最新值进行调用。
通过使用 combine,我们可以将缓存的网络查找与我们的数据库查询结合起来。它们都将同时在不同的协程上运行。这意味着当 Room 启动网络请求时,Retrofit 可以启动网络查询。然后,一旦两个 flow 的结果都可用,它将调用 combine lambda,我们在其中将加载的排序顺序应用于加载的植物。
要探索 combine 运算符如何工作,请修改 customSortFlow,使其在 onStart 中带有显著延迟地发出两次,如下所示
// Create a flow that calls a single function
private val customSortFlow = plantsListSortOrderCache::getOrAwait.asFlow()
.onStart {
emit(listOf())
delay(1500)
}
转换 onStart 将在观察者在其他运算符之前监听时发生,并且它可以发出占位符值。因此,我们在这里发出一个空列表,将调用 getOrAwait 延迟 1500 毫秒,然后继续原始 flow。如果您现在运行应用,您会看到 Room 数据库查询立即返回,与空列表结合(这意味着它将按字母顺序排序)。然后大约 1500 毫秒后,它应用自定义排序。
在继续 Codelab 之前,从 customSortFlow 中移除 onStart 转换。
Flow 和主线程安全
Flow 可以调用主线程安全函数,就像我们在这里做的,它将保留协程通常的主线程安全保证。无论是 Room 还是 Retrofit 都将提供主线程安全,我们无需再做任何事情来使用 Flow 进行网络请求或数据库查询。
这个 flow 已经使用了以下线程
plantService.customPlantSortOrder在 Retrofit 线程上运行(它调用Call.enqueue)getPlantsFlow将在 Room Executor 上运行查询applySort将在收集器调度程序上运行(在本例中是Dispatchers.Main)
因此,如果我们所做的只是在 Retrofit 中调用 suspend 函数并使用 Room flow,我们就无需为了主线程安全问题而使此代码复杂化。
但是,随着我们的数据集大小的增长,对 applySort 的调用可能会变得足够慢以阻塞主线程。Flow 提供了一个声明式 API,称为 flowOn,用于控制 flow 在哪个线程上运行。
像这样将 flowOn 添加到 plantsFlow 中
PlantRepository.kt
private val customSortFlow = plantsListSortOrderCache::getOrAwait.asFlow()
val plantsFlow: Flow<List<Plant>>
get() = plantDao.getPlantsFlow()
.combine(customSortFlow) { plants, sortOrder ->
plants.applySort(sortOrder)
}
.flowOn(defaultDispatcher)
.conflate()
调用 flowOn 对代码执行方式有两个重要影响
- 在
defaultDispatcher(在本例中为Dispatchers.Default)上启动一个新的协程,以在调用flowOn之前运行和收集 flow。 - 引入缓冲区以便将新协程的结果发送到后续调用。
- 在
flowOn之后将该缓冲区中的值发出到Flow中。在这种情况下,这指的是ViewModel中的asLiveData。
这与 withContext 切换调度程序的方式非常相似,但它确实在我们转换中间引入了一个缓冲区,这改变了 flow 的工作方式。由 flowOn 启动的协程可以比调用者消耗结果的速度更快地产生结果,并且默认情况下会缓冲大量结果。
在这种情况下,我们计划将结果发送到 UI,所以我们只关心最新结果。这就是 conflate 运算符的作用——它修改 flowOn 的缓冲区,使其只存储最后一个结果。如果在前一个结果被读取之前有另一个结果进来,它就会被覆盖。
运行应用
如果您再次运行应用,您应该会看到您现在正在使用 Flow 加载数据并应用自定义排序顺序!由于我们尚未实现 switchMap,因此过滤选项无效。
在下一步中,我们将介绍另一种使用 flow 提供主线程安全的方法。
12. 在两个 flow 之间切换
为了完成此 API 的 flow 版本,打开 PlantListViewModel.kt,我们将在其中根据 GrowZone 在 flow 之间切换,就像我们在 LiveData 版本中所做的那样。
在 plants liveData 下面添加以下代码
PlantListViewModel.kt
private val growZoneFlow = MutableStateFlow<GrowZone>(NoGrowZone)
val plantsUsingFlow: LiveData<List<Plant>> = growZoneFlow.flatMapLatest { growZone ->
if (growZone == NoGrowZone) {
plantRepository.plantsFlow
} else {
plantRepository.getPlantsWithGrowZoneFlow(growZone)
}
}.asLiveData()
此模式展示了如何将事件(生长区域更改)集成到 flow 中。它的功能与 LiveData.switchMap 版本完全相同 – 根据事件在两个数据源之间切换。
逐步讲解代码
PlantListViewModel.kt
private val growZoneFlow = MutableStateFlow<GrowZone>(NoGrowZone)
这将定义一个新的 MutableStateFlow,其初始值为 NoGrowZone。这是一种特殊的 Flow 值 holder,仅持有它接收到的最后一个值。它是一个线程安全的并发原语,因此您可以同时从多个线程写入它(并且被认为是“最后”的那个将获胜)。
您还可以订阅以获取当前值的更新。总的来说,它的行为类似于 LiveData——它只持有最后一个值并允许您观察其更改。
PlantListViewModel.kt
val plantsUsingFlow: LiveData<List<Plant>> = growZoneFlow.flatMapLatest { growZone ->
StateFlow 也是一个常规的 Flow,因此您可以像通常一样使用所有运算符。
在这里,我们使用 flatMapLatest 运算符,它与 LiveData 中的 switchMap 完全相同。每当 growZone 的值改变时,此 lambda 将被应用,并且它必须返回一个 Flow。然后,返回的 Flow 将被用作所有下游运算符的 Flow。
基本上,这允许我们根据 growZone 的值在不同的 flow 之间切换。
PlantListViewModel.kt
if (growZone == NoGrowZone) {
plantRepository.plantsFlow
} else {
plantRepository.getPlantsWithGrowZoneFlow(growZone)
}
在 flatMapLatest 内部,我们根据 growZone 进行切换。这段代码与 LiveData.switchMap 版本几乎完全相同,唯一的区别是它返回 Flows 而不是 LiveDatas。
PlantListViewModel.kt
}.asLiveData()
最后,我们将 Flow 转换为 LiveData,因为我们的 Fragment 期望我们从 ViewModel 中暴露一个 LiveData。
更改 StateFlow 的值
要让应用知道过滤器的更改,我们可以设置 MutableStateFlow.value。这是将事件传达给协程(就像我们在这里做的那样)的一种简单方法。
PlantListViewModel.kt
fun setGrowZoneNumber(num: Int) {
growZone.value = GrowZone(num)
growZoneFlow.value = GrowZone(num)
launchDataLoad {
plantRepository.tryUpdateRecentPlantsForGrowZoneCache(GrowZone(num)) }
}
fun clearGrowZoneNumber() {
growZone.value = NoGrowZone
growZoneFlow.value = NoGrowZone
launchDataLoad {
plantRepository.tryUpdateRecentPlantsCache()
}
}
再次运行应用
如果您再次运行应用,过滤器现在对 LiveData 版本和 Flow 版本都有效!
在下一步中,我们将把自定义排序应用于 getPlantsWithGrowZoneFlow。
13. 结合 flow 风格
Flow 最令人兴奋的特性之一是它对 suspend 函数的一流支持。flow 构建器和几乎所有转换都暴露了一个 suspend 运算符,可以调用任何 suspending 函数。因此,网络和数据库调用的主线程安全以及协调多个异步操作都可以通过从 flow 内部调用常规 suspend 函数来完成。
实际上,这允许您自然地将声明式转换与命令式代码混合使用。正如您在此示例中看到的,在常规的 map 运算符内部,您可以协调多个异步操作,而无需应用任何额外的转换。在很多地方,这比完全声明式方法中的等效代码更简单。
使用 suspend 函数协调异步工作
为了结束我们对 Flow 的探索,我们将使用 suspend 运算符应用自定义排序。
打开 PlantRepository.kt 并向 getPlantsWithGrowZoneNumberFlow 添加一个 map 转换。
PlantRepository.kt
fun getPlantsWithGrowZoneFlow(growZone: GrowZone): Flow<List<Plant>> {
return plantDao.getPlantsWithGrowZoneNumberFlow(growZone.number)
.map { plantList ->
val sortOrderFromNetwork = plantsListSortOrderCache.getOrAwait()
val nextValue = plantList.applyMainSafeSort(sortOrderFromNetwork)
nextValue
}
}
通过依赖常规的 suspend 函数来处理异步工作,即使此 map 操作结合了两个异步操作,它也是主线程安全的。
每当数据库返回结果时,我们将获取缓存的排序顺序——如果尚未准备好,它将等待异步网络请求。然后,一旦我们有了排序顺序,就可以安全地调用 applyMainSafeSort,它将在默认调度程序上运行排序。
通过将主线程安全问题推迟到常规的 suspend 函数,此代码现在完全是主线程安全的。它比在 plantsFlow 中实现的相同转换要简单得多。
然而,值得注意的是,它的执行方式会略有不同。每次数据库发出新值时,都会获取缓存的值。这是可以的,因为我们在 plantsListSortOrderCache 中正确缓存了它,但如果这启动了一个新的网络请求,则此实现会产生许多不必要的网络请求。此外,在 .combine 版本中,网络请求和数据库查询是并发运行的,而在此版本中,它们是顺序运行的。
由于这些差异,没有明确的规则来构造此代码。在许多情况下,使用 suspending 转换(就像我们在这里所做的那样)是可以的,这使得所有异步操作都按顺序执行。然而,在其他情况下,最好使用运算符来控制并发并提供主线程安全。
14. 使用 flow 控制并发
您快成功了!作为最后一个(可选)步骤,让我们将网络请求移到基于 flow 的协程中。
通过这样做,我们将从 onClick 调用的 handler 中移除进行网络调用的逻辑,并从 growZone 驱动它们。这有助于我们创建一个单一的事实来源并避免代码重复——任何代码都无法在不刷新缓存的情况下更改过滤器。
打开 PlantListViewModel.kt,并在 init 块中添加以下内容
PlantListViewModel.kt
init {
clearGrowZoneNumber()
growZone.mapLatest { growZone ->
_spinner.value = true
if (growZone == NoGrowZone) {
plantRepository.tryUpdateRecentPlantsCache()
} else {
plantRepository.tryUpdateRecentPlantsForGrowZoneCache(growZone)
}
}
.onEach { _spinner.value = false }
.catch { throwable -> _snackbar.value = throwable.message }
.launchIn(viewModelScope)
}
这段代码将启动一个新的协程来观察发送到 growZoneChannel 的值。您现在可以注释掉下面方法中的网络调用,因为它们仅适用于 LiveData 版本。
PlantListViewModel.kt
fun setGrowZoneNumber(num: Int) {
growZone.value = GrowZone(num)
growZoneFlow.value = GrowZone(num)
// launchDataLoad {
// plantRepository.tryUpdateRecentPlantsForGrowZoneCache(GrowZone(num))
// }
}
fun clearGrowZoneNumber() {
growZone.value = NoGrowZone
growZoneFlow.value = NoGrowZone
// launchDataLoad {
// plantRepository.tryUpdateRecentPlantsCache()
// }
}
再次运行应用
如果您现在再次运行应用,您会看到网络刷新现在由 growZone 控制!我们大大改进了代码,随着更多更改过滤器的途径的出现,通道充当了活动过滤器的单一事实来源。这样,网络请求和当前过滤器永远不会不同步。
逐步讲解代码
让我们一次逐步讲解所有使用过的新函数,从外部开始
PlantListViewModel.kt
growZone
// ...
.launchIn(viewModelScope)
这次,我们使用 launchIn 运算符来在我们的 ViewModel 内部收集 flow。
运算符 launchIn 创建一个新的协程并收集 flow 中的每个值。它将在提供的 CoroutineScope 中启动——在本例中是 viewModelScope。这很好,因为这意味着当此 ViewModel 清除时,收集将被取消。
不提供任何其他运算符时,这不会做太多事情——但是由于 Flow 在其所有运算符中都提供了 suspending lambda,因此很容易根据每个值进行异步操作。
PlantListViewModel.kt
.mapLatest { growZone ->
_spinner.value = true
if (growZone == NoGrowZone) {
plantRepository.tryUpdateRecentPlantsCache()
} else {
plantRepository.tryUpdateRecentPlantsForGrowZoneCache(growZone)
}
}
这就是神奇之处——mapLatest 将对每个值应用此 map 函数。然而,与常规的 map 不同,它会为每次调用 map 转换启动一个新的协程 (coroutine)。然后,如果在先前的协程完成之前,growZoneChannel 发射了一个新值,它将在启动新协程之前取消先前的协程。
我们可以使用 mapLatest 来为我们控制并发。flow 转换可以处理取消/重启逻辑,而无需我们自己构建。与手动编写相同的取消逻辑相比,此代码节省了大量的代码和复杂性。
Flow 的取消遵循协程的正常协作式取消规则。
PlantListViewModel.kt
.onEach { _spinner.value = false }
.catch { throwable -> _snackbar.value = throwable.message }
onEach 将在它上面的 flow 每次发射一个值时被调用。这里我们用它来在处理完成后重置微调器 (spinner)。
catch 运算符将捕获在其上方 flow 中抛出的任何异常。它可以向 flow 发射一个新值,例如错误状态,将异常重新抛回 flow 中,或者执行我们在这里正在做的工作。
当发生错误时,我们只是告诉 _snackbar 显示错误消息。
总结
这一步向您展示了如何使用 Flow 控制并发,以及如何在不依赖 UI 观察者的情况下在 ViewModel 中使用 Flow。
作为挑战步骤,请尝试定义一个函数,用以下签名封装此 flow 的数据加载
fun <T> loadDataFor(source: StateFlow<T>, block: suspend (T) -> Unit) {